Wprowadzenie
Interfejs Programowania Aplikacji (Application Programming Interface, API), to zestaw narzędzi, protokołów i definicji, które umożliwiają różnym aplikacjom komunikację między sobą. Innymi słowy, to metoda dostępu do zasobów określonych witryn, alternatywna wobec klasycznego klikania w linki i przechodzenia ze strony na stronę. API pozwala wyszukiwać i pozyskiwać dane i zasoby (np. metadane i skany) do dalszej analizy, może być też wykorzystane jako źródło, z którego korzystać będzie jakaś aplikacja. W tej lekcji poznamy podstawy korzystania z API na przykładzie danych gromadzonych i udostępnianych przez Metropolitan Museum of Art.
Cele lekcji
Celem lekcji jest:
- poznanie podstaw protokołu HTTP jako metody komunikacji z interfejsem programistycznym (API),
- poznanie podstaw pracy z interfejsem programistycznym (API) w celu pozyskiwania informacji o zbiorach cyfrowych,
- podstawy formatu JSON.
Efekty
- wiedza o podstawach HTTP,
- umiejętność wysyłania podstawowych żądań do API,
- znajomość formatu JSON.
Wymagania
Do korzystania z lekcji konieczna jest przeglądarka internetowa, najlepiej Firefox, która domyślnie formatuje dane JSON do czytelnej postaci. W trakcie lekcji korzystać będziemy z serwisu REQBIN, pozwalającego testować żądania wysyłane do API dowolnej witryny.
Część merytoryczna
Nowojorskie Metropolitan Museum of Art (Met) jest jedym z najbardziej znanych muzeów sztuki na świecie. Założone w 1870 roku, posiada dzieła takich artystów jak Rembrandt, Vermeer, Cézanne, Monet, Gauguin czy van Gogh. W zbiorach muzeum znajdują się jednak nie tylko obiekty sztuki, ale niesamowite artefakty takie jak broń i uzbrojenie, ceramika użytkowa czy stroje.
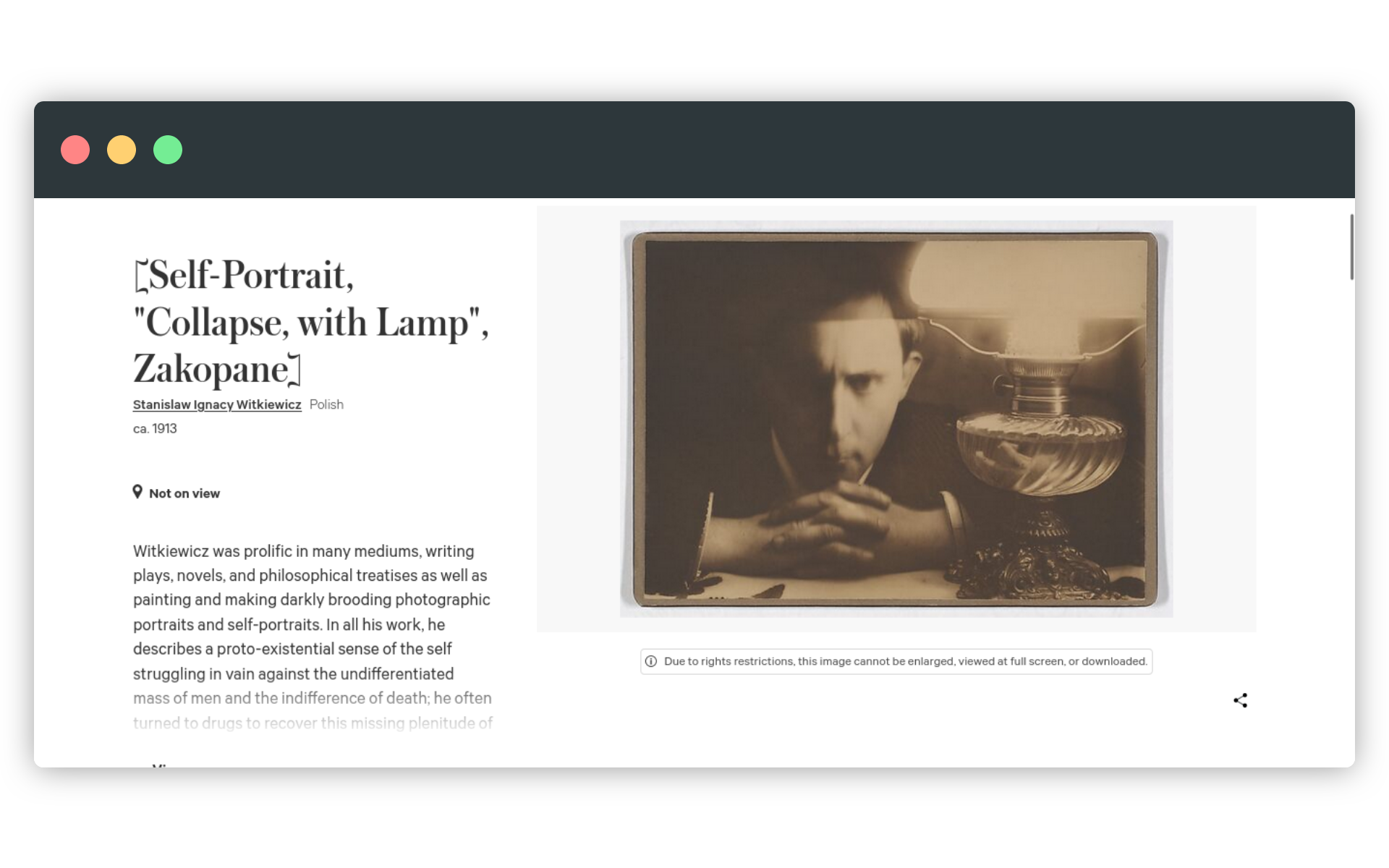
Tysiące cyfrowych reprodukcji zbiorów Met dostępnych jest na stronie muzeum cyfrowego. Przeglądanie tych zbiorów za pomocą katalogu kolekcji czy wyszukiwarki to podstawowy sposób na zapoznanie się z nimi. Witryna muzeum jest przyjazna, informacje o obiektach są czytelne, możemy też pobrać na dysk skany i fotografie obiektów z domeny publicznej - i to w plikach dobrej jakości, bez znaku wodnego. Niekiedy prawnoautorski status obiektu może być dyskusyjny - jak w przypadku tej fotografii Witkacego:
API - alternatywny sposób dostępu do zbiorów
W niektórych przypadkach przeglądanie witryny Met nie będzie specjalnie efektywne. Gdybyśmy chcieli prowadzić badania nad wybranymi zbiorami - i musieli przejrzeć kilka czy kilkadziesiąt tysięcy obiektów, wybieranie kolejnych linków i kopiowanie metadanych czy wizerunków byłoby zbyt czasochłonne i uciążliwe. Istnieje jednak inny sposób korzystania ze zbiorów dziedzictwa, udostępnianych przez muzea, biblioteki czy archiwa. Sposób ten pozwala na bezpośrednie pozyskanie informacji o obiektach, łącznie z informacjami o adresach URL plików graficznych ze skanami czy fotografiami. W tym przypadku nie oczekujemy przyjaznej, estetycznej witryny - warstwa graficzna w dotarciu do informacji w ogóle nas nie interesuje. Potrzebujemy danych i liczymy na to, że dostaniemy wyłącznie dane, które następnie będziemy mogli przeglądać i opracować, np. w Excelu.
Wszystkie strony internetowe zbudowane są z elementów języka HTML, który strukturyzuje informacje na nich dostępne, odpowiada za ich układ i niekiedy sposób wyświetlania. Aby przetworzyć HTML na dane, korzystamy z języka XPath w ramach web scrapingu, o czym wspominałem w jednej z poprzednich lekcji. Wygodniej byłoby jednak od razu otrzymać dane zamiast ciężko pracować nad ich wyodrębnieniem z setek czy tysięcy podstron witryny.
Interfejs Programowania Aplikacji (Application Programming Interface, API) pozwala na bezpośredni dostęp do danych. Sprawdźmy to na przykładzie Met. Muzeum wystawiające API powinno udostępnić nam:
- ogólne informacje o danych dostępnych za pomocą API, w tym informacje o ich strukturze i formacie oraz o relacji między API a bazą danych, np. o tym jaka część zasobów bazy danych jest udostępniana przez interfejs programistyczny, czy są stosowane jakieś filtry. W przypadku Met mamy możliwość korzystania przez API wyłącznie ze zbiorów z domeny publicznej, a to oczywiście nie wszystkie obiekty ze zbiorów tego muzeum,
- informacje o konieczności autoryzacji przy korzystaniu z API (autoryzacja nie zawsze jest potrzebna, z API Met Museum korzystamy swobodnie),
- informacje o limitach zapytań (requestów), niezbędne w przypadku maszynowego, masowego pozyskiwania danych,
- adres końcowy (endpoint): adres URL, na którym budować będziemy kwerendy,
- informacje o metodach konstruowania kwerend,
- informacje o strukturze danych (obiektów), które będą zwracane przez serwer,
- informacje o obsłudze stronicowania - już przypadku odpowiedzi zawierających dziesiątki obiektów może pojawić się konieczność wyświetlania ich na kolejnych stronach,
- nie wszystkie żądania mogą być skuteczne - dokumentacja API powinna opisywać podstawowe błędy, jakie mogą pojawić się przy pozyskiwaniu danych,
- informacje o prawach autorskich do pozyskanych danych - w przypadku Met to domena publiczna / CC0.
Dokumentacja API Met Museum publikuje część informacji z tej listy - zdecydowanie wystarczy to do przeprowadzenia naszych ćwiczeń w ramach tej lekcji. Jak widać, API to nie proste umieszczanie danych w internecie, a raczej cały system komunikacji z serwerem, pozwalający użytkownikowi (czy aplikacji) na generowanie określonych zestawów danych za pomocą manipulacji odpowiednim adresem URL.
Jak rozmawiać z serwerem?
A skoro adres URL, to i HTTP (Hypertext Transfer Protocol) - protokół odpowiedzialny za wyświetlanie w naszych przeglądarkach stron internetowych, pobieranie z nich plików czy wysyłanie formularzy. Komunikacja HTTP (np. między przeglądarką a serwerem, który publikuje stronę WWW) polega na tym, że przeglądarka - po wpisaniu przez nas adresu URL - wysyła odpowiednie żądanie do serwera, a ten odpowiada jej w standardowy sposób. Standard HTTP obsługuje kilka rodzajów żądań, nas interesować będzie głównie GET i POST. W komunikacji przeglądarka - serwer wysyłane są także nagłówki HTTP, czyli metadane na temat wielkości zwracanych danych czy ich kodowania. Z naszego punktu widzenia kluczowe mogą być nagłówki informujące o tym, jaka jest pełna liczba zwracanych obiektów - pozwala to na przygotowanie żądań o kolejne strony wyników.
Więcej na temat HTTP znaleźć można na stronie MdM Web Docs, skąd skopiowałem ten schemat pokazujący, jak dzięki zapytaniom GET generowana jest w przeglądarce prosta strona WWW zawierająca dokument HTML, grafiki i reklamy:
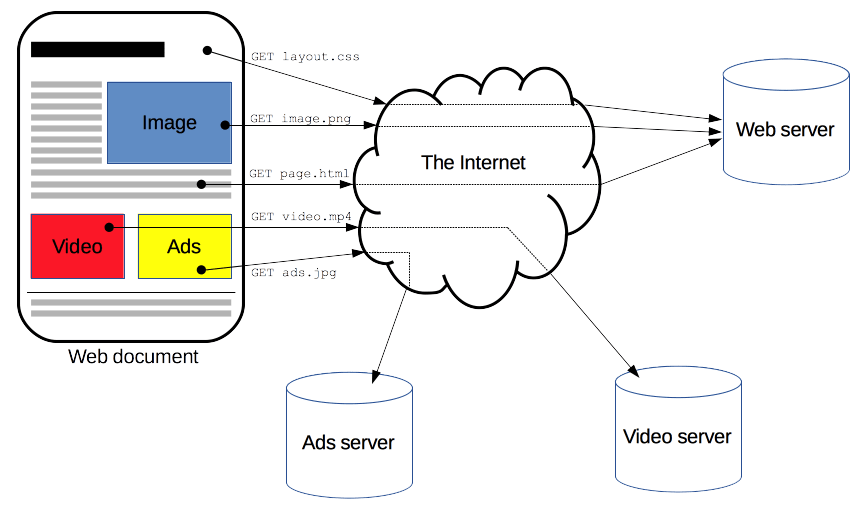
Korzystając z API zobaczymy, że serwer potrafi zwracać nie tylko strony WWW, grafiki czy pliki binarne, które możemy sobie pobrać na dysk, ale też zestawy danych.
Dane, które nie zmieszczą się w Excelu
W momencie przygotowywania tej lekcji, Met Museum udostępnia przez swoje API dane na temat 470 tys. obiektów z kolekcji. To oczywiście zdecydowanie zbyt wiele jak na pliki excelowe, do tego zestaw informacji o tych obiektach nie bardzo mieści się w prostej strukturze tabeli. Zobaczmy sobie obiekt przytoczony w dokumentacji API - to Przepiórka i proso, malunek na jedwabiu siedemnastowiecznej japońskiej twórczyni Kiyohary Yukinobu. W witrynie MET obiekt ten prezentuje się następująco:
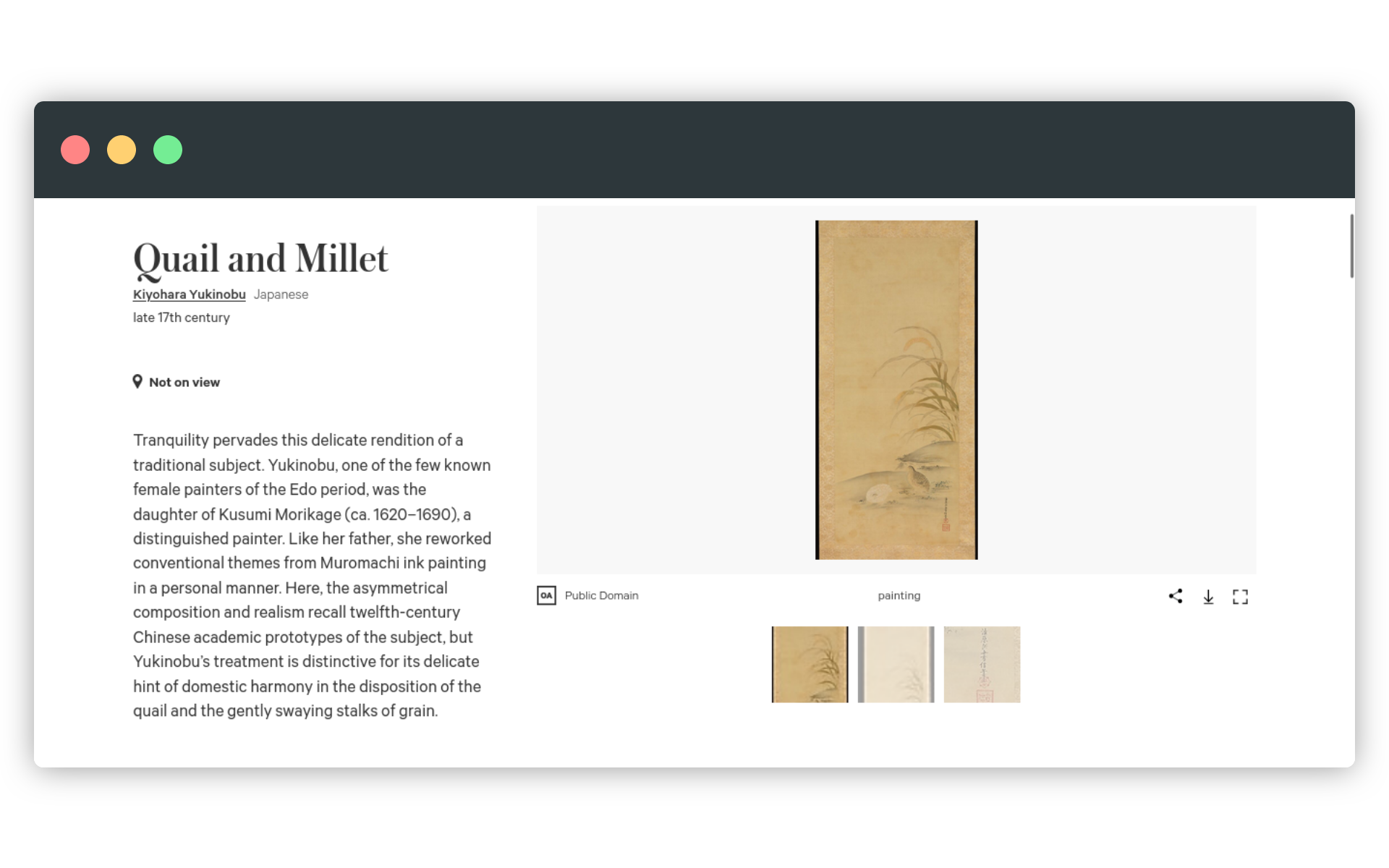
W API dzieło to jest po prostu jednym z obiektów JSON. JSON to skrót od JavaScript Object Notation. Jest to lekki (tekstowy) i czytelny dla człowieka format do przechowywania i wymiany danych. W formacie JSON dane przechowywane są tablicach i obiektach - każdy obiekt może zawierać w sobie tablice, ale też obiekty mogą być zestawiane w tablice. Podstawową strukturą JSON jest przy tym para: klucz i wartość. Ten format danych jest powszechnie wykorzystywany w komunikacji z API. W tej postaci dzieło Kiyohary Yukinobu prezentuje się następująco:
{
"objectID":45734,
"isHighlight":false,
"accessionNumber":"36.100.45",
"accessionYear":"1936",
"isPublicDomain":true,
"primaryImage":"https://images.metmuseum.org/CRDImages/as/original/DP251139.jpg",
"primaryImageSmall":"https://images.metmuseum.org/CRDImages/as/web-large/DP251139.jpg",
"additionalImages":[
"https://images.metmuseum.org/CRDImages/as/original/DP251138.jpg",
"https://images.metmuseum.org/CRDImages/as/original/DP251120.jpg"
],
"constituents":[
{
"constituentID":11986,
"role":"Artist",
"name":"Kiyohara Yukinobu",
"constituentULAN_URL":"http://vocab.getty.edu/page/ulan/500034433",
"constituentWikidata_URL":"https://www.wikidata.org/wiki/Q11560527",
"gender":"Female"
}
],
"department":"Asian Art",
"objectName":"Hanging scroll",
"title":"Quail and Millet",
"culture":"Japan",
"period":"Edo period (1615–1868)",
"dynasty":"",
"reign":"",
"portfolio":"",
"artistRole":"Artist",
"artistPrefix":"",
"artistDisplayName":"Kiyohara Yukinobu",
"artistDisplayBio":"Japanese, 1643–1682",
"artistSuffix":"",
"artistAlphaSort":"Kiyohara Yukinobu",
"artistNationality":"Japanese",
"artistBeginDate":"1643",
"artistEndDate":"1682",
"artistGender":"Female",
"artistWikidata_URL":"https://www.wikidata.org/wiki/Q11560527",
"artistULAN_URL":"http://vocab.getty.edu/page/ulan/500034433",
"objectDate":"late 17th century",
"objectBeginDate":1667,
"objectEndDate":1682,
"medium":"Hanging scroll; ink and color on silk",
"dimensions":"46 5/8 x 18 3/4 in. (118.4 x 47.6 cm)",
"measurements":[
{
"elementName":"Overall",
"elementDescription":null,
"elementMeasurements":{
"Height":118.4,
"Width":47.6
}
}
],
"creditLine":"The Howard Mansfield Collection, Purchase, Rogers Fund, 1936",
"geographyType":"",
"city":"",
"state":"",
"county":"",
"country":"",
"region":"",
"subregion":"",
"locale":"",
"locus":"",
"excavation":"",
"river":"",
"classification":"Paintings",
"rightsAndReproduction":"",
"linkResource":"",
"metadataDate":"2022-10-20T04:55:06.267Z",
"repository":"Metropolitan Museum of Art, New York, NY",
"objectURL":"https://www.metmuseum.org/art/collection/search/45734",
"tags":[
{
"term":"Birds",
"AAT_URL":"http://vocab.getty.edu/page/aat/300266506",
"Wikidata_URL":"https://www.wikidata.org/wiki/Q5113"
}
],
"objectWikidata_URL":"https://www.wikidata.org/wiki/Q29910832",
"isTimelineWork":false,
"GalleryNumber":""
}Jeśli spojrzymy uważniej na zawartość obiektu JSON, który opisuje pracę Yukinobu, możemy zauważyć, że:
- zawiera on dane różnego typu. Ciągiem tekstowym, zamkniętym cudzysłowami, jest np. wartość klucza objectName. Tablicą jest wartość klucza additionalImages - znajdują się w niej dwa odnośniki do plików graficznych z reprodukcją. Wartość klucza isPublicDomain jest typu logicznego i przyjmuje wartość true lub false. Pod kluczem objectID znajdziemy liczbę, natomiast w kluczu constituents - wyróżnianą nawiasami kwadratowymi listę zawierającą jeden obiekt, opisany nawiasami klamrowymi. Niektóre wartości przypisane do kluczy są puste.
- JSON jest formatem tekstowym, więc nie może zawierać w sobie plików graficznych - możliwe jest jednak umieszczenie odnośników do tych plików w wybranym kluczu,
- korzystając z API Met Museum i pobierając obiekty otrzymujemy od razu podstawową informację o twórcy czy twórczyni dzieła, wśród informacji o obiektach znajdują się odnośniki do Wikidanych, serwisu, z którym mieliśmy już do czynienia w jednej z poprzednich lekcji.
Dzieło Kiyohary Yukinobu trudno byłoby przetworzyć na excelową tabelę. Na szczęście JSON pozwala na przechowywanie złożonych struktur danych, takich jak obiekty zagnieżdżone (w naszym przypadku informacje o autorce) i tablice wielowymiarowe, co umożliwia bardziej elastyczne reprezentowanie danych niż tradycyjna tabela excelowa, która jest ograniczona do dwuwymiarowej struktury.
Poniżej dane w postaci JSON, ilustrujące możliwe struktury danych w tym formacie:
{
"obiekt": {
"pierwsze_pole": "wartość_1",
"drugie_pole": 123,
"trzecie_pole": true,
"czwarte_pole": null,
"zagniezdzony_obiekt": {
"zagniezdzony_pierwsze_pole": "zagniezdzona_wartosc_1",
"zagniezdzony_drugie_pole": 456
}
},
"tablica_obiektow": [
{
"pierwsze_pole": "wartość_a",
"drugie_pole": 456,
"trzecie_pole": false,
"tablica_d": [10, 20, 30],
"zagniezdzony_obiekt": {
"zagniezdzony_pierwsze_pole": "zagniezdzona_wartosc_2",
"zagniezdzony_drugie_pole": 789
}
},
{
"pierwsze_pole": "wartość_b",
"drugie_pole": 789,
"trzecie_pole": true,
"tablica_d": [40, 50, 60],
"zagniezdzony_obiekt": {
"zagniezdzony_pierwsze_pole": "zagniezdzona_wartosc_3",
"zagniezdzony_drugie_pole": 101112
}
}
],
"pusta_tablica": [],
"tablica_liczb": [1, 2, 3, 4, 5],
"klucze_z_wartosciami_logicznymi": {
"wartosc_1": true,
"wartosc_2": false
},
"klucze_puste": {
"puste_pole_1": "",
"puste_pole_2": null
}
}Zapoznając się z API warto zwrócić uwagę na klucze w strukturze prezentowanych danych. Jest duża szansa, że przynajmniej część z nich będzie mogło stać się podstawą wyszukiwania.
Szukamy Witkacego przez API
Czas przygotować i wysłać nasz pierwszy request (żądanie) do API muzeum. W tym celu skorzystamy z serwisu REQBIN, chociaż równie dobrze moglibyśmy po prostu wkleić odpowiednio skonstruowany link do paska adresu przeglądarki. Spójrzmy jednak najpierw na dokumentację, aby dowiedzieć się, jak przygotować adres żądania:
| ELEMENT URL | WARTOŚĆ |
|---|---|
| endpoint | https://collectionapi.metmuseum.org/public/collection/v1/search? |
| klucz i wartość | artistOrCulture=true |
| łącznik zapytania (AND) | & |
| klucz z frazą wyszukiwania | q=Witkiewicz |
Pełna postać adresu żądania to:
https://collectionapi.metmuseum.org/public/collection/v1/search?artistOrCulture=true&q=WitkiewiczDokumentacja API informuje też, że żądania wysyłane muszą być metodą GET. Skoro wiemy już wszystko na temat tego, jak przygotować taki request, spróbujmy go wysłać do API, korzystając z REQBIN. Wchodzimy na reqbin.com i wypełniamy pole adresu.
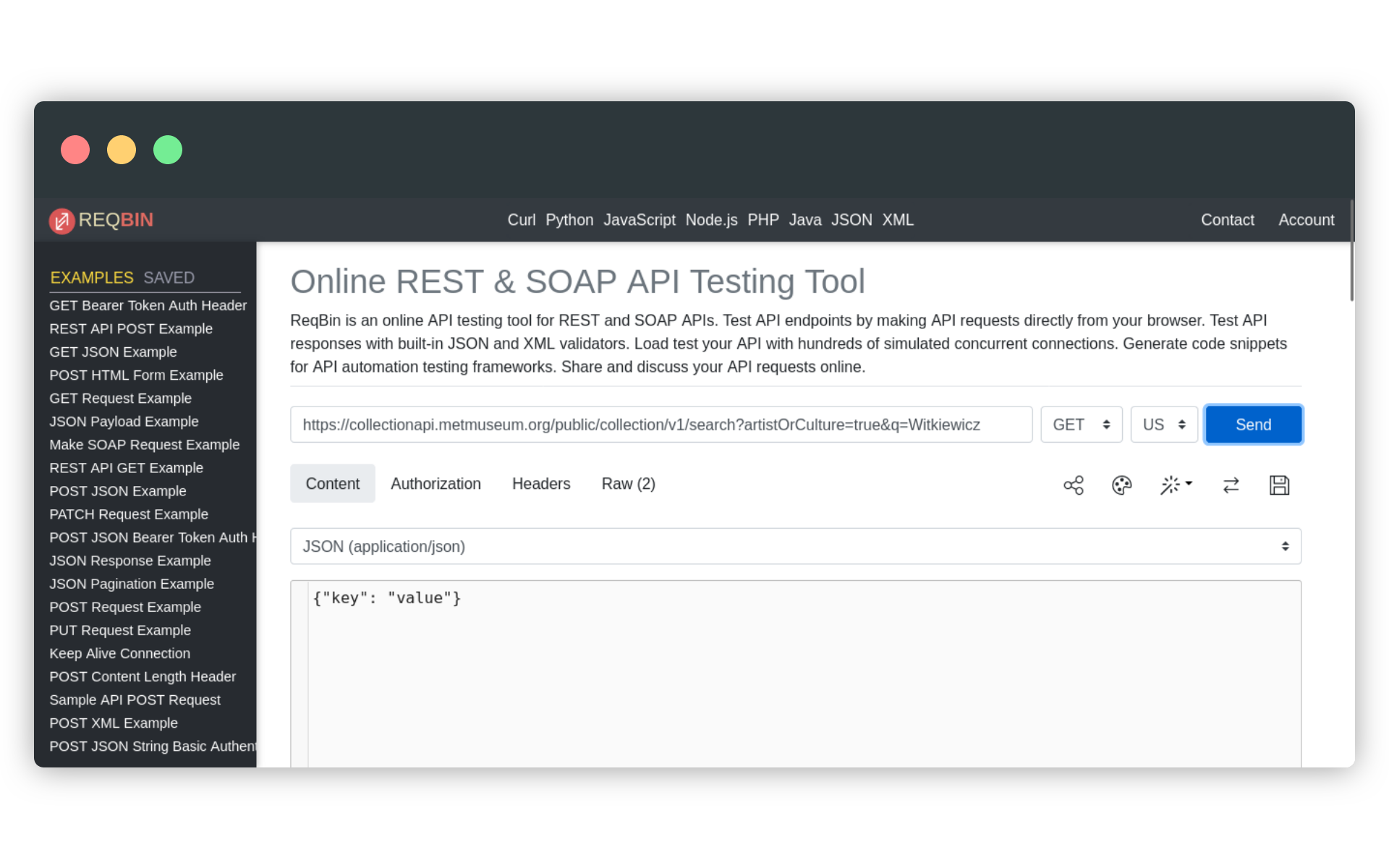
W odpowiedzi otrzymujemy nagłówki HTTP (które możemy sobie podejrzeć w zakładce Headers) oraz obiekt JSON, zawierający informację o liczbie znalezionych prac Witkiewicza oraz ich identyfikatorach:
{
"total":6,
"objectIDs":[
286054,
286234,
286232,
283263,
286233,
286235
]
}Wracamy do dokumentacji API i przygotowujemy kolejny request. Spróbujemy pozyskać informacje o obiekcie o identyfikatorze 286054. Warto zwrócić uwagę, że teraz zmieni się endpoint i serwerowi API wysyłamy jedynie identyfikator dzieła:
| ELEMENT URL | WARTOŚĆ |
|---|---|
| endpoint | https://collectionapi.metmuseum.org/public/collection/v1/objects/ |
| wartość bez klucza | 286054 |
Pełna postać adresu żądania to:
https://collectionapi.metmuseum.org/public/collection/v1/objects/286054Otrzymaliśmy informacje o obiekcie, o którym wspomniałem na początku lekcji. To fotografia z 1913 roku, oznaczona mimo tego informacją o zastrzeżeniu praw autorskich. Dlatego w obiekcie nie znajdziemy bezpośrednich linków do skanów - Met jest w stanie swobodnie udostępnić nam metadane tego dzieła, ale nie jego wizerunek.
{
"objectID":286054,
"isHighlight":false,
"accessionNumber":"2005.100.899",
"accessionYear":"2005",
"isPublicDomain":false,
"primaryImage":"",
"primaryImageSmall":"",
"additionalImages":[
],
"constituents":[
{
"constituentID":162750,
"role":"Artist",
"name":"Stanislaw Ignacy Witkiewicz",
"constituentULAN_URL":"http://vocab.getty.edu/page/ulan/500028450",
"constituentWikidata_URL":"https://www.wikidata.org/wiki/Q381238",
"gender":""
}
],
"department":"Photographs",
"objectName":"Photograph",
"title":"[Self-Portrait, \"Collapse, with Lamp\", Zakopane]",
"culture":"",
"period":"",
"dynasty":"",
"reign":"",
"portfolio":"",
"artistRole":"Artist",
"artistPrefix":"",
"artistDisplayName":"Stanislaw Ignacy Witkiewicz",
"artistDisplayBio":"Polish, Warsaw 1885–1939 Jeziory",
"artistSuffix":"",
"artistAlphaSort":"Witkiewicz, Stanislaw Ignacy",
"artistNationality":"Polish",
"artistBeginDate":"1885",
"artistEndDate":"1939",
"artistGender":"",
"artistWikidata_URL":"https://www.wikidata.org/wiki/Q381238",
"artistULAN_URL":"http://vocab.getty.edu/page/ulan/500028450",
"objectDate":"ca. 1913",
"objectBeginDate":1912,
"objectEndDate":1914,
"medium":"Gelatin silver print",
"dimensions":"Image: 13 x 18.1 cm (5 1/8 x 7 1/8 in.)",
"measurements":[
{
"elementName":"Image",
"elementDescription":null,
"elementMeasurements":{
"Height":13.017526,
"Width":18.097536
}
}
],
"creditLine":"Gilman Collection, Museum Purchase, 2005",
"geographyType":"",
"city":"",
"state":"",
"county":"",
"country":"",
"region":"",
"subregion":"",
"locale":"",
"locus":"",
"excavation":"",
"river":"",
"classification":"Photographs",
"rightsAndReproduction":"",
"linkResource":"",
"metadataDate":"2021-09-17T04:35:35.247Z",
"repository":"Metropolitan Museum of Art, New York, NY",
"objectURL":"https://www.metmuseum.org/art/collection/search/286054",
"tags":[
{
"term":"Men",
"AAT_URL":"http://vocab.getty.edu/page/aat/300025928",
"Wikidata_URL":"https://www.wikidata.org/wiki/Q8441"
},
{
"term":"Self-portraits",
"AAT_URL":"http://vocab.getty.edu/page/aat/300124534",
"Wikidata_URL":"https://www.wikidata.org/wiki/Q192110"
}
],
"objectWikidata_URL":"",
"isTimelineWork":false,
"GalleryNumber":""
}Podsumowanie
Po zakończeniu lekcji posiadamy już podstawową wiedzą o protokole HTTP. W ramach lekcji skorzystaliśmy z serwisu REQBIN, aby wysłać (właśnie za pomocą HTTP) i zanalizować żądania do API zasobów Metropolitan Museum of Art. Analizując odpowiedzi API nauczyliśmy się czytać dane w formacie JSON.
Wykorzystanie metod
Interfejsy programistyczne (API) są powszechnie wykorzystywane w działaniu aplikacji mobilnych oraz innych projektów internetowych. Wiele witryn (np. witryna Polony) wyświetla swoje zasoby korzystając z wewnętrznego API. Istnieje wiele usług i zbiorów danych, które udostępniają informacje i metody przez API.
Pomysł na warsztat
Zaproś uczestników i uczestniczki warsztatów do przeglądania zasobów wybranego muzeum, archiwum i biblioteki. Najpierw zróbcie to w standardowy sposób, poruszając się po stronach, klikając w odnośniki itp. Niech uczestnicy zanotują swoje spostrzeżenia na temat tego, co daje im taki sposób dostępu do zbiorów. Następnie niech zrobią to samo przy korzystaniu ze zbiorów z użyciem API - oczywiście konieczne będzie podstawowe wdrożenie do metod wysyłania zapytań i przeglądania odpowiedzi serwera. Przy porównywaniu obu metod dostępu warto zapytać o to, jaki wpływ na korzystanie z kolekcji muzeum ma interfejs graficzny (estetyka strony, kolory, układ treści) lub czy pozyskiwanie danych bezpośrednio z API może pozwalać na nowe spojrzenie na zbiory - przecież dla takich danych można projektować wizualizacje, wyszukiwarki, katalogi itp.


