
Wprowadzenie
Celem lekcji jest poznanie metod korzystania z Wikidanych za pomocą języka SPARQL oraz narzędzi sztucznej inteligencji, takich jak ChatGPT i Ecosia, w celu gromadzenia i prezentowania danych na temat zbiorów Muzeum Narodowego w Warszawie. W ramach lekcji poznamy podstawy danych w formacie RDF (Resource Description Framework) oraz charakter zasobów gromadzonych w Wikidanych. Posługując się ChatemGPT / Ecosią generować będziemy kwerendy w języku SPARQL, które pozwolą na zgromadzenie informacji na temat obiektów muzealnych. Wykorzystamy je także do ostatecznej prezentacji danych.
Cele lekcji
Celem lekcji jest:
- pokazanie alternatywnej metody korzystania z zasobów Wikipedii i jej siostrzanych projektów. Zamiast lektury kolejnych haseł i cierpliwego wyodrębniania z nich wybranych faktów i danych (np. przynależności instytucjonalnej określonego obiektu kultury) będziemy posługiwać się metodami maszynowymi,
- wprowadzenie do Wikidanych, danych w postaci RDF i języka SPARQL. Wikidane to otwarta baza danych, gromadząca ustrukturyzowane informacje na temat różnorodnych tematów, osób, miejsc, wydarzeń, obiektów oraz relacji między nimi. Informacje w Wikidanych dostępne są także w postaci tzw. trójek RDF (Resource Description Framework), wskazujących na relacje między obiektami w tej bazie. SPARQL (SPARQL Protocol And RDF Query Language) to język kwerend, pozwalający na pracę z danymi w postaci RDF,
- wprowadzenie do budowania kwerend z wykorzystaniem narzędzi AI. ChatGPT oraz Ecosia pozwalają na proste generowanie zapytań SPARQL, przy czym wyzwaniem jest dla nich wciąż podawanie poprawnych identyfikatorów.
Efekty
- umiejętność budowania podstawowych kwerend SPARQL do Wikidanych z wykorzystaniem narzędzi AI,
- praktyka pracy z Wikidanymi - analizowanie struktury obiektów w bazie w celu budowania odpowiednich kwerend wyszukiwawczych,
- rozumienie problemu halucynacji jako jednego z błędów narzędzi AI.
Wymagania
Lekcja wymaga dostępu do jednego z dwóch bezpłatnych narzędzi AI: ChatGPT (konieczne założenie konta po podaniu numeru telefonu) lub podobnego chata w witrynie wyszukiwarki Ecosia (bez logowania).
Część merytoryczna
W jednej z lekcji wykorzystywaliśmy narzędzia statystyczne Wikipedii do gromadzenia podstawowych danych o zbiorach Muzeum Narodowego w Warszawie, udostępnianych na Wikimedia Commons w ramach inicjatywy GLAM-Wiki. W tej lekcji pozostaniemy blisko tych zbiorów, postaramy się jednak dotrzeć do nich w inny sposób i zgromadzić na ich temat interesujące nas informacje. To, co wymagałoby od nas długiej lektury haseł wikipedystycznych, spróbujemy wykonać za pomocą zapytań maszynowych. Korzystać będziemy już jednak nie bezpośrednio z Wikipedii, ale z Wikidanych.
Struktura obiektów w Wikidanych
Wikidane to publiczna kolekcja danych, zawierająca uporządkowane informacje na temat szerokiego zakresu tematów, takich jak osoby, miejsca, wydarzenia, obiekty oraz ich wzajemne powiązania. Dane w Wikidanych są także dostępne w formie trójek RDF, które ilustrują związki pomiędzy różnymi obiektami w tej bazie. Informacje udostępniane przez Wikidane pochodzą z różnych źródeł - nie tylko z Wikipedii.
W lekcji poświęconej narzędziom statystycznym Wikipedii koncentrowaliśmy się szczególnie na jednym z obiektów Muzeum Narodowego, udostępnionym w ramach działań GLAM-Wiki. VIII-wieczny wizerunek św. Anny, odkryty podczas wykopalisk w Faras, ma swoją własną stronę w Wikimedia Commons. Wikimedia Commons to repozytorium multimediów dla wielu wikiprojektów.
Na stronie pliku znajdziemy podstawowe metadane tego dzieła. Metadane to nic innego jak uporządkowane informacje o obiekcie, dotyczące nie tylko jego treści, ale też fizycznej postaci, informujące o twórcach czy okolicznościach powstania. Jak widać, w tym przypadku to po prostu pary w schemacie: cecha - wartość cechy, np. gatunek (genre) : sztuka religijna (religious art), przedstawione osoby (depicted people) : św. Anna.
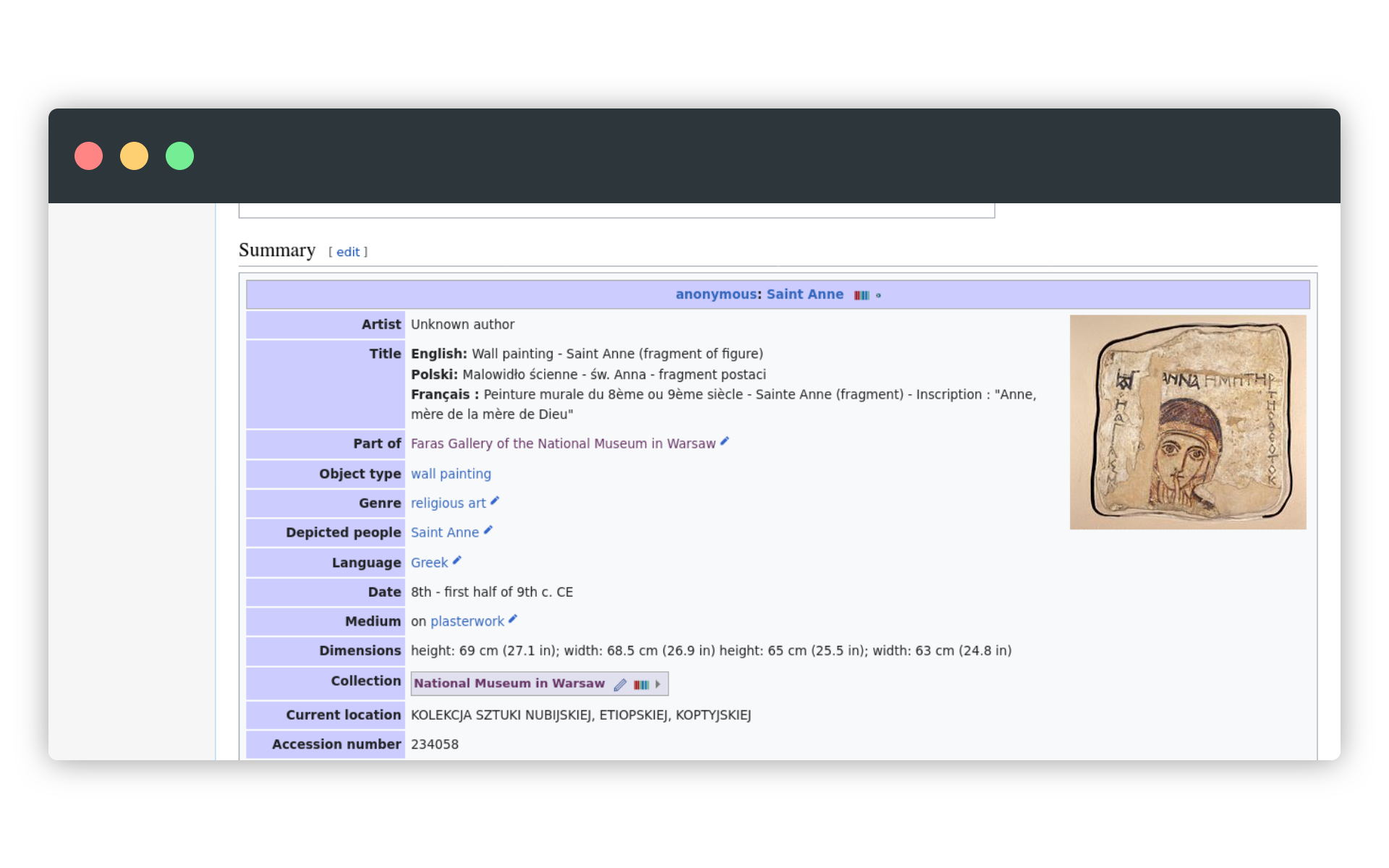
Taka postać metadanych zakłada, że rozumiemy, czym jest gatunek, kim była św. Anna i czym sztuka religijna różni się od sztuki w ogóle. Komputery nie mają jednak o tym zielonego pojęcia 🤓. Obiekty te i relacje (gatunek jest przecież pewną relacją między konkretnym dziełem sztuki a kulturą czy tradycją) muszą zostać w pewien sposób opisane, żeby komputery mogły je zrozumieć. Do tego wykorzystywany jest właśnie RDF.
Zobaczmy, jak obraz św. Anny opisany jest w Wikidanych pod identyfikatorem Q25415445. W opisie, składającym się z tabelek czy widżetów, znajdziemy jeden dotyczący gatunku (genre).
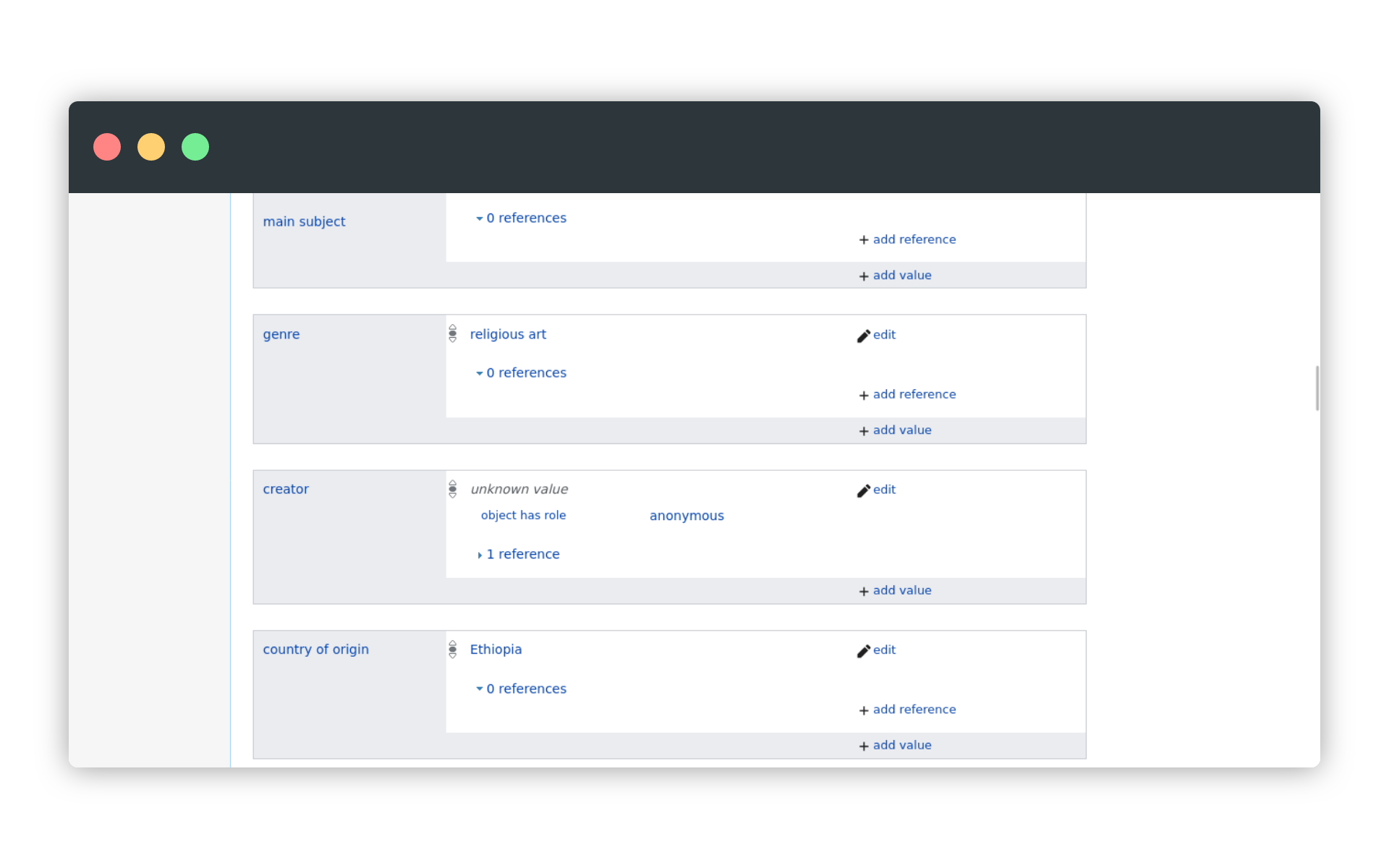
Nazwa cechy (genre) i jej wartość (religious art) są klikalne. Okazuje się, że gatunek to właściwość (property) o identyfikatorze [P136] (https://www.wikidata.org/wiki/Property:P136), a sztuka religijna - obiekt o identyfikatorze Q2864737. Wygląda to dość skomplikowanie, ale tylko pozornie. Taki model przechowywania informacji w bazie pozwala na planowanie szczegółowych kwerend. Jeśli interesują nas obiekty z kategorii malarstwo ścienne (wall painting) - identyfikator Q99516640, możemy przygotować taki schemat wyszukiwania:
POKAŻ WSZYSTKIE OBIEKTY BĘDĄCE INSTANCJĄ MALARSTWA ŚCIENNEGO (Q99516640),
KTÓRE POSIADAJĄ CECHĘ GATUNEK (P136)
O WARTOŚCI SZTUKA RELIGIJNA (Q2864737)Być może w kształcie tej kwerendy widać już pewne zdanie, złożone z podmiotu, orzeczenia i dopełnienia. Podmiotem jest obraz (instancja malarstwa ściennego), orzeczeniem wskazanie gatunku (należy do gatunku) a dopełnieniem - sztuka religijna. W języku naturalnym kwerenda brzmiałaby po prostu tak: POKAŻ WSZYSTKIE DZIEŁA MALARSTWA ŚCIENNEGO W GATUNKU SZTUKI RELIGIJNEJ.
W ten sposób można nawet opisać siebie, wystarczy skorzystać z generatora FOAF, który pozwala na stworzenie zestawu danych w postaci RDF. To, w jaki sposób wyznaczymy instancje obiektów, ich cechy i możliwe relacje zależy już od przyjętej ontologii. Ontologia w bazach danych i metadanych to kształt formalnego opisu struktury i znaczenia danych w określonym dziedzinie wiedzy. Ontologię tworzy zbiór zdefiniowanych terminów, relacji i reguł, które opisują sposób, w jaki dane są zorganizowane i jak są ze sobą powiązane w danym kontekście.
Budujemy kwerendę w SPARQL
Skoro wizerunek św. Anny z Faras jest instancją dzieła malarstwa ściennego oraz przynależy do gatunku sztuki religijnej, to może ma jeszcze inne cechy, pozwalające nam na przygotowanie kwerendy listującej informacje o zbiorach Muzeum Narodowego? Owszem, ma! Jest nią kolekcja (collection) o identyfikatorze P195. Dopełnieniem będzie oczywiście obiekt Muzeum Narodowe, który także ma własny identyfikator Q153306. Nasza kwerenda powinna więc wyglądać mniej więcej tak:
POKAŻ WSZYSTKIE OBIEKTY
KTÓRE POSIADAJĄ CECHĘ KOLEKCJA (P195)
O WARTOŚCI MUZEUM NARODOWE W WARSZAWIE (Q153306)W tym przypadku nie interesuje nas gatunek obiektu, chociaż oczywiście możemy wprowadzić taki filtr przy kolejnych zapytaniach. Kwerenda w języku naturalnym nie jest jeszcze możliwa w Wikidanych, dlatego wykorzystajmy ChatGPT / Ecosię do przygotowania zapytania w języku SPARQL. Oba narzędzia postarają się od razu wytłumaczyć nam poszczególne elementy składni. Oto prompt, jaki można wykorzystać:
Wygeneruj zapytanie SPARQL do Wikidanych, które wylistuje wszystkie obiekty udostępnione przez Muzeum Narodowe w Warszawie.ChatGPT udostępni taką odpowiedź (uwaga, będzie to odpowiedź niepoprawna!):
SELECT ?item ?itemLabel
WHERE {
?item wdt:P195 wd:Q170804.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".
}
}W treści zapytania widzimy dokładnie, że wyszukiwane są obiekty, których cecha to P195 (bycie w kolekcji jakiejś instytucji). Niestety, ChatGPT błędnie zidentyfikował tu Muzeum Narodowe w Warszawie. Zdecydowanie nie chodzi nam o obiekty będące w kolekcji jednostki strumienia indukcji magnetycznej (Q170804)! Taka kwerenda zwróciłaby zero wyników. Mamy tu do czynienia z szeroko dyskutowanym ostation halucynowaniem AI, czyli proponowaniem przez narzędzia sztucznej inteligencji odpowiedzi wyglądających na autentyczne i prawdopodobne, ale ostatecznie błędnych z powodu wewnętrznych ograniczeń modelu czy też braku bieżącego dostępu narzędzia AI do internetu.
Poprawianie halucynowanego kodu
Poprawmy zatem zapytanie, dodając prawidłowy identyfikator Muzeum Narodowego w Warszawie oraz zmieniając ustawienia języka - chcemy tytułów prac (itemLabel) w języku polskim:
SELECT ?item ?itemLabel
WHERE {
?item wdt:P195 wd:Q153306.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],pl".
}
}Kod zapytania w języku SPARQL wklejamy do konsoli Wikidanych. Poprawnie wykonana kwerenda powinna zwrócić około 12 tys. wyników! Możemy sobie wyobrazić, ile czasu zajęłoby ręczne pozyskanie tych danych z treści haseł w Wikipedii.
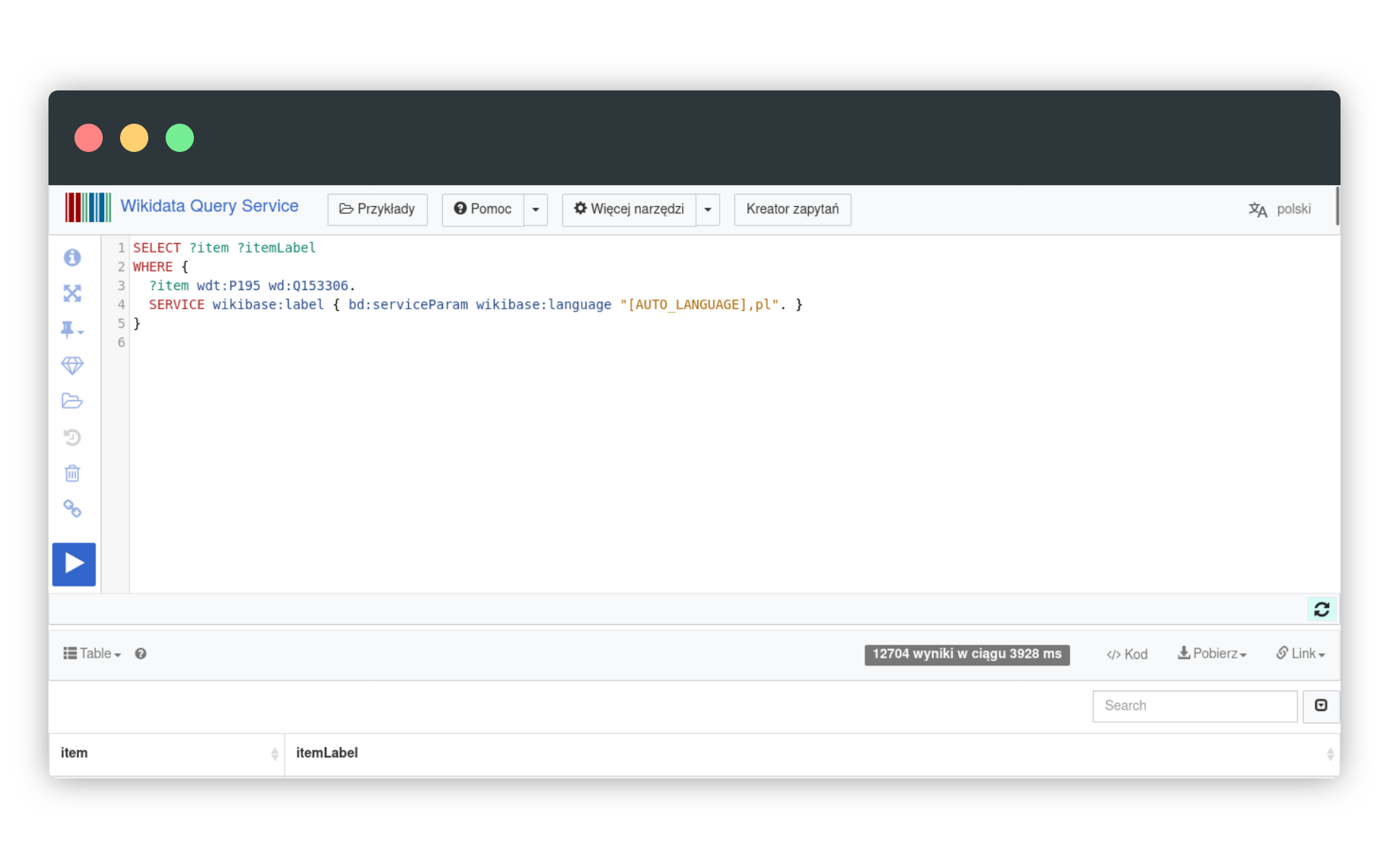
W odpowiedzi na nasze zapytanie uzyskaliśmy listę obiektów, składającą się z dwóch kolumn: pierwszej (item), zawierającej identyfikatory (adresy URL) i drugiej (itemLabel), zawierające tytuł (czy też nazwę) obiektu. Wszystkie dane możemy swobodnie pobrać na dysk w postaci CSV czy JSON.
Ponieważ w wynikach wyszukiwania mamy dostęp do identyfikatorów obiektów, w bardziej zaawansowanych kwerendach możemy wyciągać z nich dodatkowe informacje. SPARQL pozwala nawet na pozyskanie danych o obiektach i postaciach widocznych na dziełach sztuki przechowywanych w Muzeum Narodowym - ale to już temat na inną lekcję.
Podsumowanie
Kwerendy SPARQL w Wikidanych pozwalają w efektywny sposób przeszukiwać zasoby Wikipedii i innych projektów wiedzowych. Dzięki temu, że możemy bardzo dokładnie precyzować cechy interesujących nas obiektów, wyszukiwanie takie jest zdecydowanie dokładniejsze niż proste przeszukiwanie Google. Użycie ChatGPT / Ecosii ułatwia budowanie kwerend, ale nie zwalnia nas z dbałości o odpowiednie wskazanie identyfikatorów cech, obiektów czy relacji.
Dane takie jak te dostępne w Wikidanych to tzw. dane powiązane (linked data). Wyszukując obiekty prezentowane czy przechowywane w Muzeum Narodowym w Warszawie odwoływaliśmy się do powiązania między obiektami - charakter tej relacji (bycie w kolekcji) zostało w Wikidanych odpowiednio zdefiniowane.
Wykorzystanie metod
Kwerendy SPARQL w Wikidanych stanowią wartościowe narzędzie dla badaczek i praktyków zajmujących się dziedzictwem i kulturą. Pozwalają na eksplorację obszernych zbiorów danych, analizę powiązań między obiektami oraz gromadzenie danych do wizualizacji. Można wykorzystać je w pracach na temat trendów w kulturze czy w badaniach porównawczych. Dane w postaci RDF wykorzystuje się także do anotacji materiałów wizualnych oraz w budowaniu repozytoriów i wyszukiwarek zdigitalizowanych obiektów.
W 2016 roku DBpedia, semantyczna baza danych podobna Wikidanym, stała się jednym ze źródeł danych w aplikacji poświęconej europejskiej kulturze kulinarnej. Aplikacja powstała w ramach projektu Europeana Food and Drink.
Więcej o inicjatywach tego typu w sektorze dziedzictwa przeczytać można w opracowaniu Museum Linked Open Data: Ontologies, Datasets, Projects.
Pomysł na warsztat
Lekcja może być podstawą warsztatu z podstaw SPARQL w Wikidanych. Planując własny warsztat dowolnie eksperymentować można z wyborem obiektów i relacji między nimi oraz korzystać z ChatGPT / Ecosii do wsparcia przy budowie zapytań. W Wikidanych wyszukiwać można np. zabytki znajdujące się w Gdańsku, daty i miejsca publikacji dzieł wybranej autorki czy oceny filmów historycznych wyprodukowanych poza USA.
Potencjalnie wartościową modyfikacją tej lekcji byłoby zwrócenie uwagi na ograniczenia kwerend semantycznych - m.in. aktualność baz danych czy uproszczenia ich ontologii.



{kind=link}