
Wprowadzenie
Kolejna lekcja w serwisie humanistyka.dev poświęcona będzie web scrapingowi, czyli metodom pozyskiwania danych ze stron internetowych. Źródłem naszych danych będzie witryna NUKAT. NUKAT to katalog służący do przeszukiwania zasobów bibliotek naukowych z całej polski. W ramach lekcji wygenerujemy zestaw lektur na temat humanistyki cyfrowej, a następnie wyodrębnimy z niego tytuły i nazwiska autorów prac. Chociaż NUKAT pozwala na eksportowanie wyników wyszukiwania, format tego eksportu nie jest najbardziej przyjazny. Aby pozyskać tylko te dane, które nas interesują, skorzystamy z kwerend w języku XPath.
Cele lekcji
Celem lekcji jest wprowadzenie do niezależnego pozyskiwania danych ze stron WWW z wykorzystaniem języka XPath. Niezależne pozyskiwanie danych to pozyskiwanie danych, które nie potrzebuje oficjalnego dostępu do interfejsu programistycznego (API) ani żadnych narzędzi eksportu danych przygotowanych przez wydawcę witryny.
Efekty
- zrozumienie podstaw web scrapingu i zastosowanie tych metod w pozyskiwaniu danych z internetu,
- znajomość podstaw struktury strony WWW - DOM (Document Object Model) oraz języka XPath,
- zwrócenie uwagi na potencjał katalogu NUKAT w przygotowywaniu danych bibliograficznych.
Wymagania
Do skorzystania z lekcji konieczne jest zainstalowanie w przeglądarce rozszerzenia XPath Helper oraz dostęp do dowolnego arkusza kalkulacyjnego. Do analizy zebranych danych tekstowych przyda się ChatGPT, Ecosia albo podobne narzędzie.
Część merytoryczna
Dlaczego warto korzystać z katalogu NUKAT?

NUKAT to informacja. Z dowolnego miejsca na świecie uzyskasz dostęp do informacji o zasobach wielu polskich bibliotek naukowych i akademickich. Dowiesz się, w której bibliotece daną książkę, film, nuty albo czasopismo możesz wypożyczyć, obejrzeć na miejscu albo poprosić o wypożyczenie międzybiblioteczne. Z katalogiem NUKAT oszczędzasz czas, w jednym miejscu masz wiele bibliotecznych katalogów (Źródło: NUKAT)
NUKAT pozwala na przeszukiwanie setek bibliotek naukowych, dodatkowo udostępniając narzędzie do eksportowania danych wyszukiwania. Można potraktować ten katalog jako źródło danych bibliograficznych i pierwsze miejsce, w którym orientujemy się, co i kiedy napisano na interesujący nas temat. Naturalnie trzeba przy tym pamiętać, że NUKAT informuje wyłącznie o tych książkach, które są dostępne w polskich bibliotekach.
Generujmy strony wyszukiwania
Dla celów tej lekcji wyobraźmy sobie badanie na temat literatury poświęconej cyfrowej humanistyce. Chcemy zebrać dane i w prosty sposób pokazać, jakie tytuły na ten temat są dostępne i oraz wygenerować statystykę użytych w nich słów.
Już teraz możemy zainstalować wtyczkę XPath Helper, która przyda nam się w dalszej części lekcji.
Wchodzimy teraz na stronę NUKAT i w pole wyszukiwania wpisujemy słowa kluczowe: humanistyka cyfrowa. W opcjach filtrowania wyników zaznaczamy język polski, a jako typ dokumentu - książki. W momencie pisania tej lekcji, katalog zwracał informacje o 34 pozycjach - oczywiście może się to zmienić w przyszłości.
Na stronie wyników znajduje się przycisk Cała strona wyników wyszukiwania do schowka, która pozwala na zebranie bibliografii (także z wykorzystaniem różnych zapytań) i następnie wyeksportowanie jej do pliku tekstowego. Treść tego pliku jest niespecjalnie wygodnie uporządkowana, co może sprawiać trudność przy dalszym przetwarzaniu danych. Zignorujmy więc opcję schowka i postarajmy się pozyskać dane bezpośrednio ze strony. Przed nami trzy strony potencjalnych danych, które niezależnie pozyskamy z witryny katalogu NUKAT.
Podstawy pracy z DOM
Do pozyskania tych danych musimy nauczyć się podstaw języka XPath. Język XPath pozwala na precyzyjne lokalizowanie danych w dokumentach XML, ale także w strukturach danych HTML na stronach internetowych. W wydaniach cyfrowych przygotowywanych na bazie standardu TEI (Text Encoding Initiative) XPath umożliwia wyodrębnianie wybranych elementów treści takich jak tytuły, nagłówki, przypisy, nazwiska czy cytaty.
Aby zrozumieć, jak budować zapytania w tym języku, warto poznać podstawy dokumentu HTML, tzw. Document Object Model (DOM). Model obiektowy dokumentu reprezentuje strukturę dokumentu HTML, XML lub XHTML w postaci drzewa obiektów i pozwala na bezpośredni do nich dostęp. Język XPath umożliwia poruszanie się po strukturze DOM. Najłatwiej będzie to zrozumieć po wykonaniu krótkiego ćwiczenia.
Uruchamiamy wtyczkę XPath Helper na pierwszej stronie wyników. Wtyczka udostępnia dwa okna: w lewym wpisujemy poniższą kwerendę w XPath, w prawym wyświetlają się wyniki tej kwerendy.
//div[@class="recordHighlight"]/h3/a/text()Na pierwszy rzut oka ten kody wydaje się zupełnie niezrozumiały. Jednak jeśli wyświetlimy sobie kod źródłowy strony, z której chcemy pobrać dane, zobaczymy, że składa się ona z elementów, które pojawiły się w kodzie XPath.
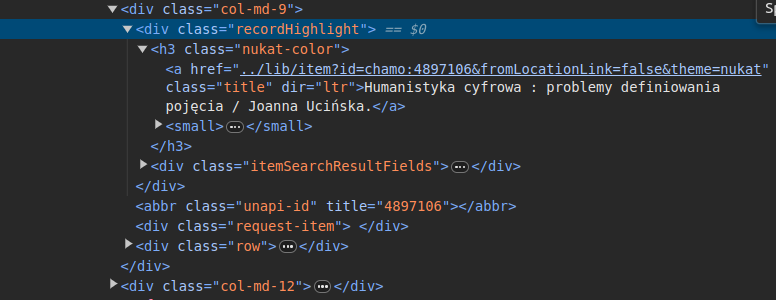
Elementami DOM są m.in. elementy języka HTML, za pomocą którego budowane (strukturyzowane) są strony WWW. Pewnie znacie podstawowe elementy HTML takie jak A (do tworzenia odnośników), IMG (to zagnieżdżania grafiki na stronie) czy BR (niespecjalnie już zgodny ze standardami 😉 element dodający nową linię). W naszym kodzie XPath odwołujemy się do takich elementów jak DIV (kontener, w który można włożyć inne elementy), H3 (nagłówek trzeciego stopnia), A (odnośnik). Jest też obsługiwana przez XPath funkcja text(), zwracająca tekst wybranego elementu.
Poza elementami (tagami), HTML, podobnie jak XML, posiada atrybuty. W elemencie A znajduje się atrybut HREF, który służy do podawania ścieżki do jakiegoś zasobu WWW. Standardy HTML opisują, jakie elementy mogą mieć jakie atrybuty, w XML-u jest w tym zdecydowanie większa dowolność - nie bez powodu XML to Rozszerzalny Język Znaczników (Extensible Markup Language).
Mamy więc treści wyników wyszukiwania z witryny NUKAT. To strona internetowa, strukturyzowana w języku HTML. Jeśli chcemy te wyniki przełożyć na dane, musimy poruszać się po tej strukturze - eksplorować elementy DOM. W web scrapingu zazwyczaj nie interesuje nas wygląd strony i jej układ wizualny. Szukamy elementów w strukturze (kodzie źródłowym).

Treści do danych: kwerenda w XPath
Przypomnijmy sobie naszą kwerendę:
//div[@class="recordHighlight"]/h3/a/text()Jej poszczególne elementy można wyjaśnić w następujący sposób:
- //div[@class=”recordHighlight”] - znajdź wszystkie elementy DIV o atrybucie class (klasa) ustawionym na recordHighlight w dowolnym miejscu dokumentu (znak // oznacza, że ignorujemy miejsce tego diva w strukturze dokumentu),
- /h3/a wewnątrz tych znalezionych elementów DIV znajdź wszystkie elementy H3, a w nich elementy A
- /text() - zwróć tekst znajdujący się wewnątrz tych znalezionych elementów A.
Dlaczego akurat taka kwerenda? Jeśli spojrzymy na kod strony wyników wyszukiwania, to tytuły wszystkich pozycji umieszczone są w znacznikach H3, umieszczonych w elemencie DIV o klasie recordHighlight. Rzeczywiście poruszamy się po drzewie DOM!
Warto dodać, że nie wszystkie kwerendy XPath muszą być bardzo skomplikowane. Przykładowo, aby pozyskać adresy linków, które umieszczone są na dowolnej stronie, wystarczy użyć zapytania:
//a/@hrefJak widać, w XPath atrybut wskazujemy za pomocą małpy @ - wcześniej wykorzystywaliśmy atrybut klasy @class. W tej kwerendzie prosimy o wszystkie elementy A (które budują linki) niezależnie od ich miejsca w strukturze, a następnie o atrybut HREF każdego z nich. W budowaniu zaawansowanych kwerend XPath możemy korzystać z pomocy ChatGTP i podobnych narzędzi. Wróćmy jednak do naszej kwerendy po tytułach pozycji.
Wyodrębione tytuły możemy wkleić do arkusza kalkulacyjnego. Po wyciągnięciu ich z pierwszej strony wyników wyszukiwania, musimy powtórzyć tę czynność dla kolejnych stron. W praktyce web scrapingu nie robi się ręcznie - wygodniej wykorzystać albo napisać program, który automatycznie wyodrębni wskazane przez nas dane z treści witryny lub zestawu stron.
Praca z listą tytułów
Tę część lekcji poświęconej XPathowi zakończyć możemy szybką analizą zestawu tytułów poświęconych cyfrowej humanistyce, którą wylistował nam NUKAT. Listę 34 tytułów pobraną z poszczególnych stron wyszukiwania łączymy ze sobą i wklejamy do ChatGPT.
Pora uporządkować pozyskane tytuły. Można zauważyć, że każdy z nich kończy się wymienieniem imienia i nazwiska autora lub autorki - na szczęście informacje te umieszczane są za znakiem /. Być może ChatGPT poradzi sobie z usunięciem tych elementów z tytułów, jeśli skorzystamy z prompta
przetwórz na tabelęi wkleimy pozyskane za pomocą XPath teksty:

Chat GPT umiejętnie oddzielił tytuły od nazwisk. Możemy teraz spróbować wygenerować odpowiednie statystyki. Aby wynik był dokładniejszy, wszystkie słowa sprowadzamy do form podstawowych:
zlematyzuj słowa w każdym wierszu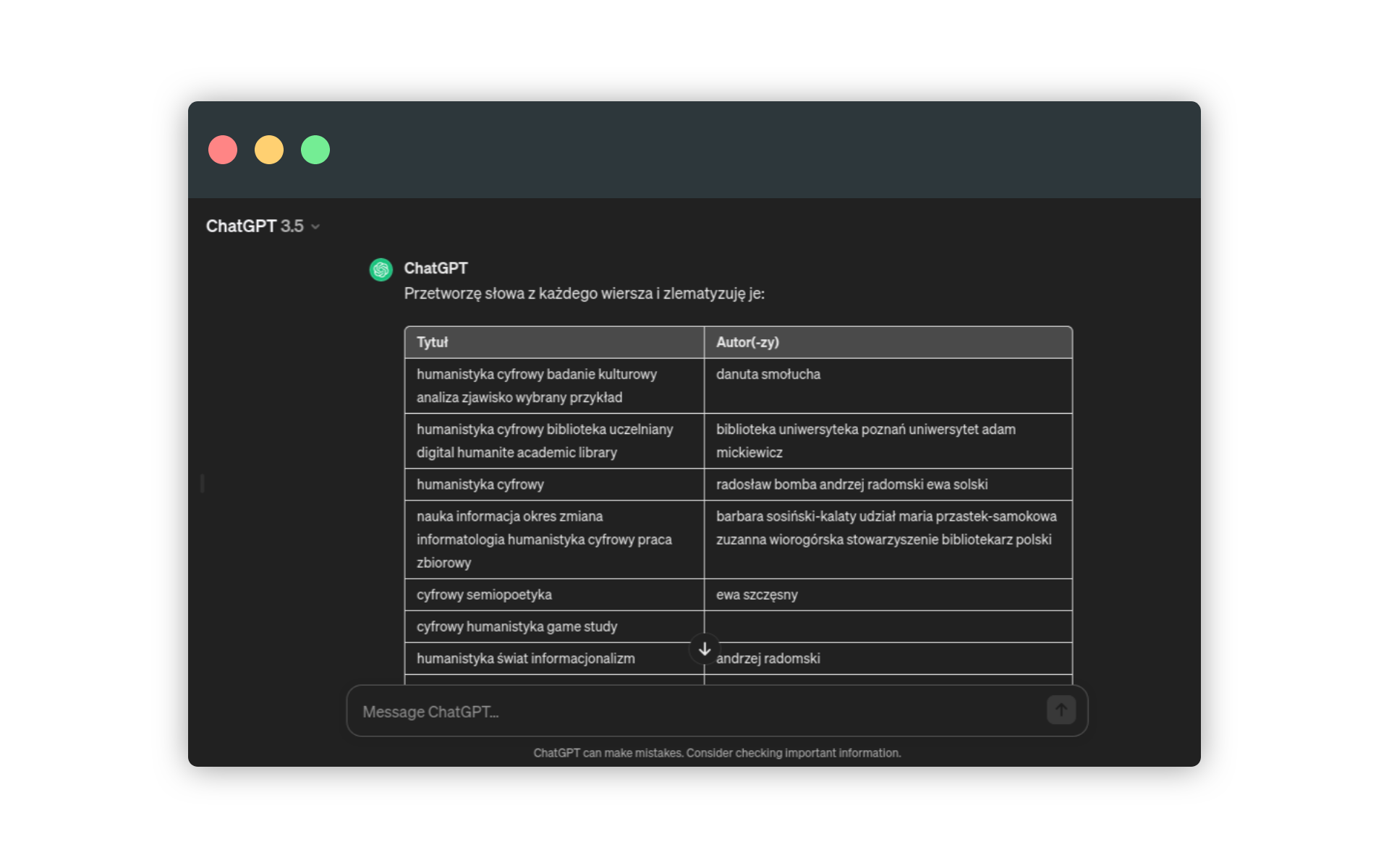
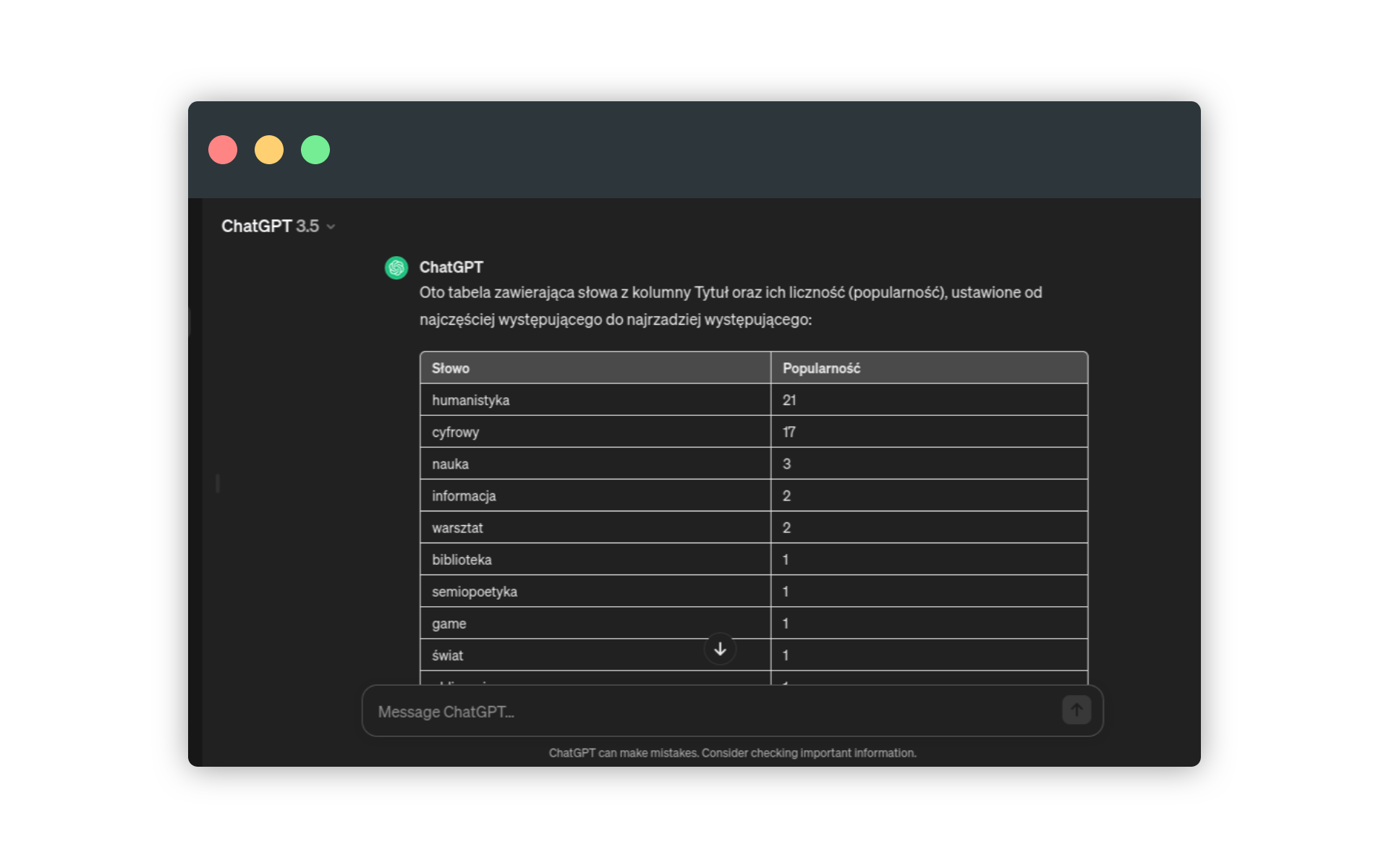
Następującym promptem generujemy statystyki słów:
policz wszystkie słowa w kolumnie Tytuł i wygeneruj tabelę, w której pojawią się dwie kolumny: słowo (każde ze słów), popularność (liczba wystąpień słowa). Ustaw słowa od najczęstszegoJakie słowa (pojęcia) najczęściej pojawiają się w tytułach prac poświęconych cyfrowej humanistyce (poza cyfrową humanistyką oczywiście 😉 )? Lista jest bardzo zróżnicowana, ale mały zestaw tytułów uniemożliwia oczywiście wyciąganie jakichkolwiek wniosków.
Podsumowanie
W ramach lekcji skorzystaliśmy z wtyczki do przeglądarki internetowej, która umożliwia wysyłanie do treści wyświetlanej strony kwerend w języku XPath. XPath pozwala poruszać się swobodnie po strukturze strony (drzewie DOM) i wyodrębniać interesujące nas informacje. W ten sposób przetwarzamy stronę WWW na zestaw danych.
Wykorzystanie metod
Zastosowaniem web scrapingu w humanistyce i badaniach społecznych jest gromadzenie danych z treści publikowanych na stronach internetowych, w tym artykułów, książek, czasopism, katalogów a nawet wyników wyszukiwania. Możliwe jest automatyczne zbieranie recenzji, komentarzy czy odnośników - to ostatnie może być wstępem do tworzenia wizualizacji sieciowych i badania połączeń między witrynami.
Warto patrzeć na strony WWW nie tylko jak na dwuwymiarowe przestrzenie prezentacji tekstu i grafiki, ale głębokie struktury potencjalnych danych. Więcej na ten temat przeczytać można w artykule The World Wide Web as Complex Data Set: Expanding the Digital Humanities into the Twentieth Century and Beyond through Internet Research.
Pomysł na warsztat
Zaproś uczestników warsztatu do wejścia na stronę wybranego muzeum cyfrowego czy biblioteki cyfrowej. Pokaż, że poza danymi udostępnionymi w standardowy sposób - np. jako lista metadanych - z zasobów muzeum czy biblioteki korzystać też można maszynowo. Zadaniem uczestników warsztatu może być wyodrębnienie wybranych danych z tych witryn (np. informacji o liczbie odsłon danego obiektu muzealnego, adresu do pliku graficznego z jego wizerunkiem czy treści przypisów).
Alternatywnie, uczestnicy warsztatu mogą próbować odpowiednio zakodować w HTML-u lub XML-u określoną treść (np. fragment tekstu dramatu) w taki sposób, aby możliwe było wykonanie na nim poprawnych kwerend XPath, np. listujących osoby dramatu, wypowiedzi wybranej postaci czy nagłówki poszczególnych scen.


