
Wprowadzenie
Modele text-to-image takie jak Midjourney, DALL-E 3, Stable Diffusion czy Ideogram 2.0 umożliwiają generowanie materiałów wizualnych na podstawie zapytań (promptów). Treść generowanego obrazu, jego format i styl, podawane są w prompcie i wyrażone bezpośrednio w języku naturalnym. Oprogramowanie wykorzystujące modele text-to-image to oczywiście nie jedyne narzędzia sztucznej inteligencji, którymi możemy maszynowo pracować z grafiką.
Celem niniejszego opracowania jest przedstawienie podstaw korzystania z maszynowego generowania i przetwarzania grafiki. W pierwszej części zostaną opisane zasady tworzenia promptów do modeli text-to-image, w drugiej - już w osobnym artykule - formy (gatunki) wypowiedzi wizualnych, które można wytwarzać automatycznie.
Maszynowe generowanie obrazów może być wykorzystywane nie tylko w działaniach marketingowych instytucji kultury, ale też w projektach edukacyjnych i działaniach artystycznych. Pierwotne zastosowanie tych metod miało zresztą wymiar artystyczny - w 1973 roku Harold Cohen opracował na Stanfordzie pierwsze wersje programów z serii AARON.
Część merytoryczna
Zawsze pracujemy z oryginalnymi wizerunkami
Pamiętajmy, że maszynowe generowanie i przetwarzanie obrazów w żaden sposób nie wyklucza korzystania z oryginalnych dzieł i wizerunków.
Po pierwsze, modele używane w tych zadaniach trenowane są na dużych zbiorach wizerunków tworzonych przez człowieka - jednym z nich jest zbiór Common Objects in Context (COCO), udostępniony przez Microsoft jeszcze w 2016 roku. Zawiera on aktualnie ponad 300 tys. fotografii oraz dane na temat 1.5 mln obiektów. Użycie do trenowania modeli
- różnorodnych zbiorów obrazów, grafik artystycznych, fotografii,
- obiektów muzealnych, zbiorów instytucji kultury i dziedzictwa,
- baz stock images,
- zasobów WikimediaCommons,
- czy zasobów platform takich jak media społecznościowe czy deviantART i ArtStation,
pozwoliło na maszynowe tworzenie wytworów wizualnych, które naśladują style artystyczne i ikoniczne przedstawienia w niezwykle sugestywny sposób.
Po drugie, dostępne są modele, za pomocą których możemy maszynowo przetwarzać stworzone przez człowieka obrazy i wizerunki. Chociaż wciąż są to modele generatywne, zakres ich działania jest ściślej niż w przypadku modeli text-to-image określony. Przykładowo, model pozwalający na usuwanie obiektów z obrazu zadziała tylko na wybranej przez człowieka przestrzeni wizerunku i po usunięciu wybranego obiektu automatycznie zakryje po nim ślad, generując odpowiednie tło.
Maszynowe generowanie obrazów: prompty
Prompt (zapytanie, zachęta) to wyrażona w języku naturalnym instrukcja, wysyłana do modelu generatywnego i zawierająca opis oczekiwanej odpowiedzi. Prompty wykorzystywane są w pracy z dużymi modelami językowymi (zob. ChatGPT w pracy instytucji kultury: prompty systemowe), można za ich pomocą generować również muzykę, obrazy i materiały wideo.
Prompt zawierać powinien opis treści obrazu oraz jego najważniejsze cechy. Warto zwrócić uwagę na to, że - przynajmniej w DALL-E - nie ma znaczenia, czy wyrażamy go w języku polskim czy angielskim (możemy swobodnie mieszać słowa). Poniżej przykład promptu, w którym część poleceń została wyrażona w języku angielskim (m.in. odwołanie do stylu Grupy Memphis):
wygeneruj obraz osób zwiedzających muzeum sztuki i robiących telefonami zdjęcia jednemu popularnemu obiektowi - zielonemu bananowi. Niech wszystkie osoby mają czułki jak kosmici. Niech obraz będzie w stylu Memphis, Memphis Group, 1980s, bold, kitch, colourful, shapes
Wygenerowana grafika nie jest dokładnie taka, jakiej żądaliśmy w prompcie - w przedstawianej scenie fotografowany obiekt nie jest zielonym bananem, ale obrazem, na którym umieszczono żółty owoc na zielonym tle. Te drobne nieścisłości można poprawić w dalszej pracy z modelem, pokazują one jednak, że nie tylko modele językowe, ale też wizualne potrafią halucynować - uzupełniają brakujące dane i dopowiadają brakujące szczegóły, kierując się prawdopodobieństwem występowania określonych elementów i cech.
Uważne przygotowywanie promptów (inżynieria promptów) pozwala ograniczyć halucynowanie także w tym przypadku. Aby uzyskiwać lepsze efekty w pracy z modelami text-to-image, warto poznać podstawowe elementy efektywnego prompta.
Nassim Dehouchea i Kullathida Dehouche w opracowaniu What’s in a text-to-image prompt? The potential of stable diffusion in visual arts education (2023) zanalizowali zestaw ponad 72 tys. promptów wykorzystywanych do pracy ze Stable Diffusion, aby na tej podstawie zaproponować ogólny schemat promptowania do modeli text-to-image.
Części składowe promptu
Prompt zawierać może nie tylko opis treści obrazu oraz jego cechy gatunkowe, estetyczne czy techniczne, ale też bezpośrednie odniesienia do kultury i sztuki. Autorzy opracowania przekonują, że możemy odwoływać się nie tylko do konkretnych twórców i twórczyń czy ruchów artystycznych, ale nawet do recepcji (popularny, nagrodzony, arcydzieło):
| Temat | Opis |
|---|---|
| Przedmiot | Postacie i obiekty widoczne na obrazie, takie jak cyborg, dwa psy, samochód, czarodziej itd. |
| Medium | Rodzaj obiektu wizualnego, jaki ma być wygenerowany, np. ilustracja cyfrowa, fotografia, obiekt 3D, sztuka konceptualna, plakat itd. |
| Technika | Narzędzia i oprogramowanie użyte do stworzenia obrazu, np. Blender, obiektyw typu pincushion, Unreal engine, Octane itd. |
| Gatunek | Cechy estetyczne opisujące gatunek artystyczny obrazu, np. anime, surrealizm, barok, fotorealizm, sci-fi, czarno-biały, epicka fantasy, film noir itd. |
| Nastrój | Cechy opisujące atmosferę i emocje obrazu, takie jak piękny, niesamowity, ponury itd. |
| Ton | Cechy opisujące chromatyczną kompozycję obrazu, np. pastelowy, kolory synthwave, eteryczne kolory itd. |
| Oświetlenie | Użycie światła i cieni na obrazie, np. ciemne, kinematograficzne oświetlenie, realistyczne oświetlenie cieniowane, studyjne oświetlenie, promienne światło itd. |
| Rozdzielczość | Cechy opisujące poziom szczegółowości obrazu, np. bardzo szczegółowy, fotorealistyczny, 100 mm, 8K, 16K, HQ, ostry fokus itd. |
| Odniesienia artystyczne | Artyści lub dzieła sztuki używane jako inspiracja, np. Greg Rutkowski, Studio Ghibli, Artgerm, Zaha Hadid itd. |
| Odbiór/Popularność | Nagrody, uznanie lub status popularności na platformach artystycznych, np. popularny na Artstation, arcydzieło, nagrodzony itd. |
Źródło: Dehouche, N., & Dehouche, K. (2023). What’s in a text-to-image prompt? The potential of stable diffusion in visual arts education. Heliyon, 9(6), doi.org/10.1016/j.heliyon.2023.e16757
Z treści ponad 70 tys. przebadanych promptów autorzy wyodrębnili też drugorzędne elementy opisu, odnoszące się - znów - nie tylko do treści obrazu, ale też jego estetyki, cech technicznych czy potencjalnej recepcji:
| Temat | Opis |
|---|---|
| Fizyczne atrybuty przedmiotu | rasa, wiek, ubranie, akcesoria, uroczy, glamour, pulchny itd. |
| Emocjonalne lub psychologiczne cechy przedmiotu | szczęśliwy, zaniepokojony, zwycięski, zamyślony itd. |
| Środowisko/Sceneria | czas, pogoda, średniowieczny, postapokaliptyczny itd. |
| Symetria/Powtórzenie | symetria, symetryczny, wzór, motyw, fraktal itd. |
| Głębia ostrości | rozmyte tło, głębia ostrości, przysłona, F/4, F/2.8, ostry fokus, bokeh itd. |
| Kąt | ultraszeroki kąt, widok zenitalny, widok filmowy, zbliżenie itd. |
| Przesłanie/Znaczenie | propaganda, religijny, reklama itd. |
Źródło: Dehouche, N., & Dehouche, K. (2023). What’s in a text-to-image prompt? The potential of stable diffusion in visual arts education. Heliyon, 9(6), doi.org/10.1016/j.heliyon.2023.e16757
Inżynieria odwrotna zapytania
Być może dobrą metodą nauki pisania promptów jest analizowanie ich pod kątem elementów składowych. Oto nieco skomplikowany prompt, generujący obraz w obrazie:
mockup wiszącego na ceglanej ścianie w kawiarni plakatu przedstawiającego renesansowy portret kota w kryzie w stylu vaporwave z podpisem humanistyka.dev
Za pomocą zapytania
z podanego w cudzysłowiu promptu do DALL-E wydziel elementy pasujące do kategorii: przedmiot, medium, technika, gatunek, nastrój, ton, oświetlenie, rozdzielczość, odniesienia artystyczne, odbiór/popularność i wyświetl je jako tabelę "mockup wiszącego na ceglanej ścianie w kawiarni plakatu przedstawiającego renesansowy portret kota w kryzie w stylu vaporwave z podpisem humanistyka.dev"możemy otrzymać gotowe zestawienie elementów oryginalnego prompta i w razie potrzeby zmieniać i uzupełniać wybrane wartości poszczególnych elementów:
| Kategoria | Element |
|---|---|
| Przedmiot | plakat |
| Medium | digital art, mockup |
| Technika | styl vaporwave, renesansowy portret |
| Gatunek | portret |
| Nastrój | zabawny, nieco nostalgiczny |
| Ton | lekki, humorystyczny |
| Oświetlenie | nie określono |
| Rozdzielczość | nie określono |
| Odniesienia artystyczne | renesans, vaporwave |
| Odbiór/popularność | kawiarnia, estetyka retro |
W naszym przypadku możemy uzupełnić zapytanie o opis oświetlenia - światło w kawiarni może być przyciemnione i nastrojowe, a kolorowy plakat prezentować się może w nim zdecydowanie lepiej.
wygeneruj mockup wiszącego na ceglanej ścianie w kawiarni plakatu przedstawiającego renesansowy portret kota w kryzie w stylu vaporwave z podpisem humanistyka.dev słabe nastrojowe oświetlenie plakat świecący w mroku
W razie potrzeby możemy też uploadować do modelu wybrany obraz wzorcowy, żądać wygenerowania na jego podstawie promptu i już dalej go przetwarzać. Taka opcja dostępna jest np. w płatnej wersji ChatGPT (w którym korzystamy z modeli DALL-E). Na tej platformie możemy też bezpośrednio edytować wybrane fragmenty wygenerowanego obrazu, co pozwala zachować spójność kolejnych jego wersji.
Stronniczość modeli text-to-image
Nassim Dehouchea i Kullathida Dehouche w swojej analizie oszacowali też ilościową zawartość wymienionych wyżej elementów promptów do modelu text-to-image. Okazuje się, że prawie 20 proc. tokenów (fragmentów) tekstów promptów stanowiły odniesienia do konkretnych artystów czy stylów artystycznych. Odniesienia te dominowały w puli promptów, były nawet częstsze niż wskazania tematu obrazu lub jego gatunku!
Udało im się też zebrać dane na temat najbardziej popularnych wartości elementu odniesienia artystyczne:
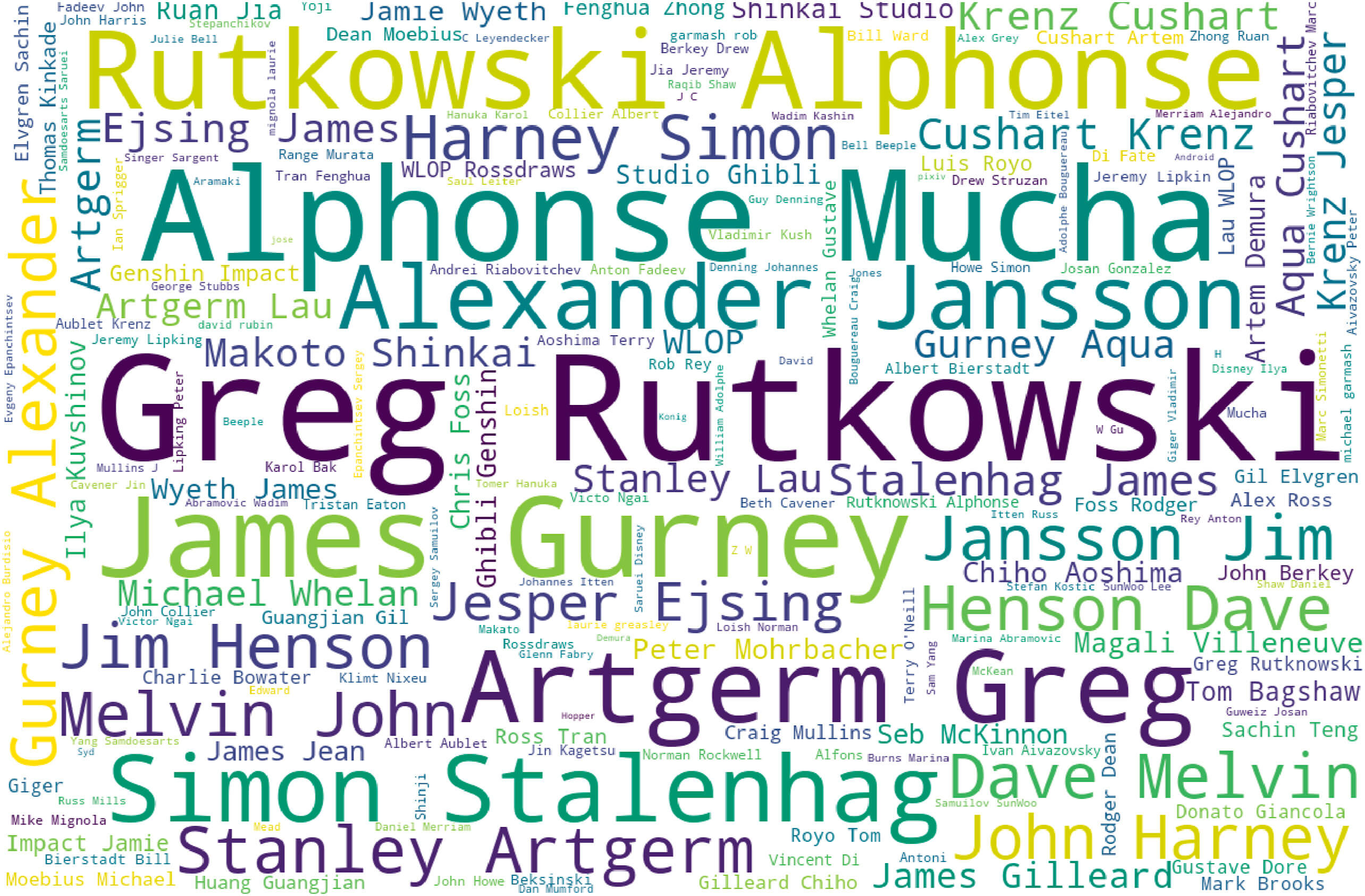
Źródło: Dehouche, N., & Dehouche, K. (2023). What’s in a text-to-image prompt? The potential of stable diffusion in visual arts education. Heliyon, 9(6), doi.org/10.1016/j.heliyon.2023.e16757
Style dostępne w modelach generowania obrazów zależą od zasobów, na których je trenowano. Oznacza to, że tu także - jak w przypadku modeli językowych - mamy do czynienia ze stronniczością (bias), np. dotyczącą płci, koloru skóry czy kontekstu kulturowego.
O ile stronniczość dotyczącą płci czy koloru skóry możemy poprawiać, dopracowując treść prompta, to trudno nam odwoływać się w nim do kontekstu, jakiego nasz model nie zna. W poniższym żądaniu DALL-E użyliśmy pojęcia dom podcieniowy oraz Żuławy, których DALL-E najprawdopodobniej poprawnie nie identyfikuje:
wygeneruj realistyczną fotografię zabytkowego domu podcieniowego na Żuławach, użyj perspektywy - widok z drona z góry na dom i podwórze, szeroki kąt, okolica rolnicza i nizinna, jesienny dzień
Użycie niemieckiego pojęcia Vorlaubenhaus pozwoliło nieco poprawić jakość wygenerowanego obrazu (inna, bardziej poprawna bryła oraz pruski mur). Być może problem z poprzednim promptem polegał też na języku - model trenowano na zasobach, które opisano jako Vorlaubenhaus. Angielskie pojęcie arcaded house, którego używa ChatGPT w podsumowaniu zadania generowania obrazu, nie opisuje przecież dokładnie tego, czym jest żuławski dom podcieniowy.
wygeneruj realistyczną fotografię zabytkowego domu podcieniowego Vorlaubenhaus na Żuławach, użyj perspektywy - widok z drona z góry na dom i podwórze, szeroki kąt, okolica rolnicza i nizinna, jesienny dzień
Innym powodem niskiej jakości odpowiedzi może być ogólna trudność modeli text-to-image w replikowaniu wizerunków rzeczywistych, skomplikowanych obiektów. Podobne jak z domem podcieniowym trudności mielibyśmy z pewnością przy próbie wygenerowania miniatury na stronie średniowiecznego kodeksu czy Pałacu Kultury i Nauki. W tym ostatnim przypadku model wygenerował niemal poprawną bryłę budynku, ale układ ulic i panorama w tle są już całkowicie halucynowane:
wygeneruj full shot (shows full subject + surroundings) pałac kultury i nauki w warszawie
Dostępne style obrazów generatywnych
Wobec takich ograniczeń i stronniczości modeli, warto poznać rozpoznawane przez nich style. Tylko korzystając z dostępnych dla modeli stylów i odwołań będziemy w stanie skuteczniej generować obrazy.
Oczywiście trudno liczyć na dokładnie opracowaną, zamkniętą listę słów i pojęć - modele generatywne to systemy black box i, przynajmniej jako zwyczajni użytkownicy, nie do końca wiemy, na jakiej podstawie podejmowane są decyzje co do konkretnych szczegółów tworzonego obrazu. Możemy jednak skorzystać z rozmaitych podpowiedzi. Jednym z ciekawych materiałów na ten temat są opracowania typu prompt book, pokazujące możliwe wartości części składowych promptów i ilustrujące je odpowiednimi przykładami. W prompt booku opracowanym przez serwis dallery.gallery (2022) znajdziemy propozycje fraz opisujących określone estetyki wizualne, związane z techniką tworzenia obrazu (nacisk pędzla lub ołówka, kolory, postać obrazu itp.):

Przygotowano także zestawy fraz opisujące określone style z historii sztuki:

Określenia stylów w prompcie nie zawsze muszą odwoływać się do nurtów i pojęć znanych z historii sztuki. Eksperymentując z modelami text-to-image możemy korzystać ze stylów i estetyk internetowych, których obszerną listę możemy znaleźć także tutaj:
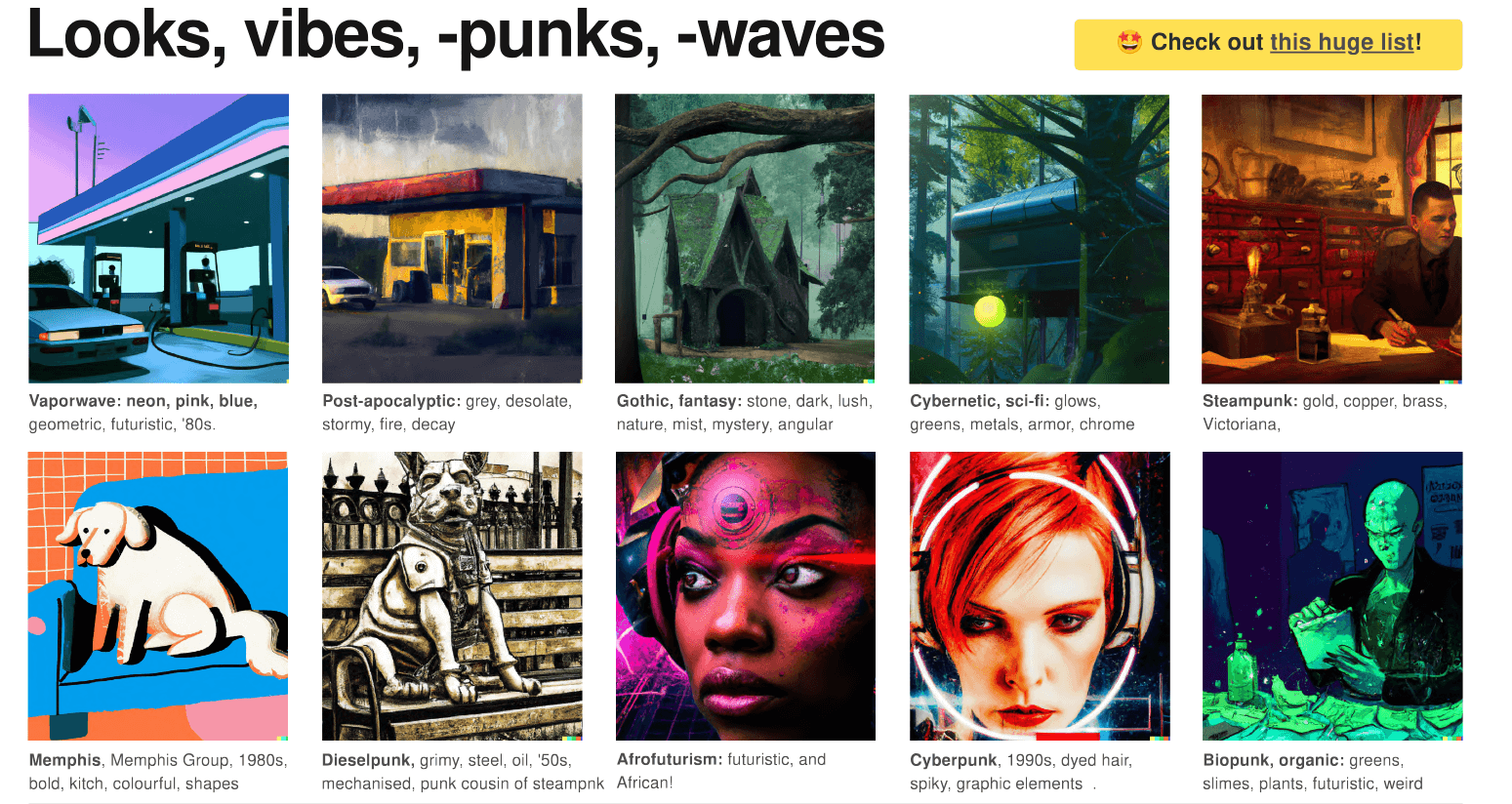
Ogólny schemat promptu do generowania obrazów
Cytowani wyżej Nassim Dehouchea i Kullathida Dehouche analizują prompty, odwołując się do tradycyjnych koncepcji fotograficznych - kompozycji, oświetlenia i stylu. Każdym promptem możemy odpowiadać na trzy pytania:
- CO: mise en scène - temat, układ obiektów, scenografii i aktorów w kadrze lub scenie, symetria, emocje,
- JAK: dispositif - urządzenie, zastosowanie, układ - w tym przypadku programy i techniki postprodukcji. Jeśli mise-en-scène oznacza to, co jest wyświetlane na obrazie, dispositif byłoby sposobem, w jaki jest ono tworzone. W tej części promptu ustalamy technikę obrazu, rozdzielczość, kąt patrzenia, ton kolorów itp.,
- W JAKIM CELU: obiekt kulturowy - ten element promptu opisuje obiekt twórczości artysty, rozumiany jako artefakt i jako cel. Ustalamy tutaj medium, gatunek, odniesienia do dzieł sztuki, przekaz i potencjalną recepcję.
Budując treść promptu z tych trzech części zapewniamy sobie pokrycie najważniejszych elementów opisu obiektu wizualnego, przez co wygenerowany obraz może bardziej odpowiadać naszym oczekiwaniom.
Uważajmy na slop!
Maszynowe generowanie obrazów pozwala w łatwy sposób, bez żadnych umiejętności, tworzyć wiele wizerunków, niekiedy o dość skomplikowanej treści. To idealne narzędzie dla spamerów i osób, które chcą zarabiać na pozyskiwaniu i przekierowywaniu ruchu internetowego. Według badaczy i badaczek ze Stanford Internet Observatory, publikowane na Facebooku posty, zawierające niskiej jakości generatywne grafiki, otrzymują setki milionów interakcji, a post zawierający obraz wygenerowany maszynowo był jednym z dwudziestu najczęściej oglądanych treści na Facebooku w III kwartale 2023 roku (pozyskał 40 mln wyświetleń). Co więcej
Obrazy generowane przez AI są wyświetlane w aktualnościach na Facebooku nawet tym użytkownikom, którzy nie obserwują tych stron. Podejrzewamy, że obrazy generowane przez AI pojawiają się w aktualnościach tych odbiorców, ponieważ algorytm rankingu Facebooka promuje treści, które mogą generować interakcje. Komentarze do obrazów generowanych przez AI sugerują, że wielu użytkowników nie jest świadomych sztucznego pochodzenia tych obrazów, nawet jeśli inni zamieszczają ostrzegające komentarze lub infografiki.
Slop to właśnie publikowane w mediach społecznościowych, na witrynach internetowych, w ebookach i w wynikach wyszukiwania zazwyczaj niechciane i złej jakości treści, zazwyczaj wizualne, generowane maszynowo. Slop nie tylko wpływa na jakość treści, z którą mamy do czynienia na platformach społecznościowych, ale nawet na wyniki wyszukiwania. Przykładowo, maszynowa interpretacja Ogrodu rozkoszy ziemskich Hieronima Boscha pojawia się w wynikach wyszukiwania Google Images wyżej niż cyfrowa reprodukcja oryginalnego dzieła.
Nie wiemy jeszcze, jak ludzie traktują slop i czy powoli nie zaczyna być utożsamiany ze spamem. Nie wiemy też, czy wykorzystanie w zwyczajnej działalności informacyjnej i promocyjnej treści wytwarzanych maszynowo (nawet lepszej jakości), jest odbierane pozytywnie. Użycie generowanych maszynowo grafik na profilach instytucji kultury czy w trakcie prezentacji na konferencjach wcale nie musi być odbierane jako wyraz instytucjonalnej nowoczesności i kompetencji, ale może zostać uznane za przejaw lenistwa, ślepe podążanie za trendami lub brak dobrego smaku.
Z jakich elementów może składać się slop? Spójrzmy na wygenerowany w DALL-E obrazek:
wygeneruj fotografię w stylu stock images corporate przestrzeni sali muzeum sztuki średniowiecznej, w której na środku stoi humanoidalny robot robiący zdjęcie eksponatowi - średniowiecznej patelni z uśmiechniętym jajkiem sadzonym w hełmie rycerskim, układ horyzontalny
Elementy, które wprowadzają niepokój przy odbiorze tego obrazka, ale też mogą intrygować i skłaniać do skomentowania, to:
- zderzenie estetyki korporacyjnej fotografii stock images z niepasującym, komiksowym elementem,
- przywołanie oczywistej i wyświechtanej metafory (humanoidalny robot reprezentujący sztuczną inteligencję),
- nielogiczne połączenie elementów: o ile robot robiący zdjęcia pasuje do przestrzeni muzeum średniowiecznego (jeśli przesłanie grafiki ma być metaforyczne), to uśmiechnięte jajko na patelni jest już całkowicie obcym elementem,
- złej jakości szczegóły grafiki (warto zwrócić uwagę na to, w jaki sposób model wygenerował obiekty ustawione przy ścianach muzeum).
Planując korzystanie z maszynowego generowania obrazów w działaniach naszej instytucji kultury, edukacji czy nauki, spróbujmy sprawdzać, czy mozolnie przygotowywana przez nas grafika ostatecznie nie uzyska cech slopu i nie wywoła nieprzyjemnego wrażenia wśród naszych odbiorców.
Podsumowanie
Nikt z nas, ani żadna instytucja, nie ma obowiązku wykorzystywać maszynowego generowania obrazów do jakichkolwiek celów. W żadnym razie używanie tego typu rozwiązań nie świadczy o innowacyjności, nowoczesności i kreatywności. Warto zastanowić się, po co nam w ogóle automatycznie tworzone wizerunki. Zwróćmy uwagę, że:
- lepiej nadają się one do ilustrowania pojęć i idei (za pomocą metafor) niż reprodukowania rzeczywistych wizerunków,
- wypracowanie dobrej jakości grafiki wymaga czasu i kompetencji (praca z wieloma promptami),
- nawet jeśli wygenerowany obrazek prezentuje się atrakcyjnie, jego szczegóły (wybrane elementy) mogą mieć bardzo niską jakość,
- istnieje duży problem halucynowania nieopisanych w prompcie elementów obrazu,
- modele text-to-image mają wysoką stronniczość (są raczej generyczne niż lokalne),
- możliwość swobodnego generowania i dopracowywania obrazów może być związana z koniecznością opłat abonamentowych,
- aplikacje korzystające z modeli sztucznej inteligencji mają stosunkowo wysokie koszty środowiskowe.
Pamiętajmy też o tym, że generowanie obrazów na podstawie czy w stylu prac dawnych i współczesnych artystów może przeinaczać intencje, które stały u powstania oryginalnych dzieł. Przy korzystaniu z modeli text-to-image pojawia się wiele pytań etycznych oraz kontrowersje, związane z potencjalnym przekraczaniem regulacji prawa autorskiego.
Twórcy i twórczynie oryginalnych obrazów i grafik mogą starać się urchronić swoje utwory przed wykorzystaniem do trenowania modeli. Przegląd metod i narzędzi takiego blokowania przygotowali redaktorzy portalu The Verge.