
Wprowadzenie
Europejska Noc Muzeów (ENM) to coroczne wydarzenie organizowane w wielu miastach Europy. Podczas tej nocy muzea, galerie sztuki, zabytki oraz inne instytucje kulturalne są otwarte dla zwiedzających. Pierwsza Noc Muzeów odbyła się w Berlinie w 1997 roku, w Polsce - w 2003 roku. Noc Muzeów to okazja do promocji oferty instytucji kultury. Odbiorców ENM opisuje opublikowane w 2014 roku badanie Anny Linek.
Noc Muzeów w Warszawie w 2024 roku odbyła się 18 maja, a informacje o wydarzeniach publikowane były na stronie Urzędu Miasta. Jeśli tak, to - w ramach ćwiczenia - możemy je pozyskać i przygotować mapę cyfrową, która pozwoli nam szybko sprawdzić, czy więcej wydarzeń organizowano na prawym, czy na lewym brzegu Wisły. Nie jest to specjalnie ambitne pytanie badawcze, ale zależy tu nam na metodzie, a nie na wynikach.
Cele lekcji
Celem lekcji jest poznanie kolejnych możliwości w pracy z mapami w R. W ćwiczeniu wykorzystamy pakiet xml2, pozwalający na wyodrębnienie treści ze strony internetowej, pakiet tidygeocoder, który pomoże nam zamienić adresy instytucji i wydarzeń na koordynaty geograficzne i oczywiście pakiet leaflet, zarządzający wyświetlaniem mapy i interakcjami.
Efekty
Efektem naszej pracy będzie mapa cyfrowa z niestandardową warstwą, zawierająca zestaw markerów uporządkowanych w klastry. Szybki rzut oka na mapę pozwoli od razu rozpoznać, w jakiej części Warszawy odbyło się więcej wydarzeń w ramach Nocy Muzeów.
Wymagania
Do skorzystania z lekcji konieczne jest zapoznanie się z lekcją poświęconą podstawą GIS oraz lekcją na temat podstaw budowy map w R. Niezbędne jest także posiadanie darmowego konta w serwisie Posit.cloud oraz znajomość podstaw R.
Część merytoryczna
Z lekcji poświęconej podstawom web scrapingu pamiętamy, że podstawą wyodrębniania danych ze stron WWW jest praca z DOM (Document Object Model). DOM reprezentuje strukturę dokumentów (HTML czy XML) i pozwala na dostęp do wybranych obiektów z tej struktury. Do poruszania się po drzewie DOM używamy języka XPath.
Wyszukiwanie danych i pobranie strony
Wchodzimy na stronę warszawskiej Nocy Muzeów i przyglądamy się jej zawartości. Pod adresem
https://nocmuzeow.um.warszawa.pl/search/#formznajdziemy formularz wyszukiwania. Zależy nam na informacji o wszystkich wydarzeniach, dlatego nie wypełniamy żadnego pola i klikamy przycisk wyszukiwania. Otrzymaliśmy listę, z której będziemy chcieli pobrać dane adresowe.
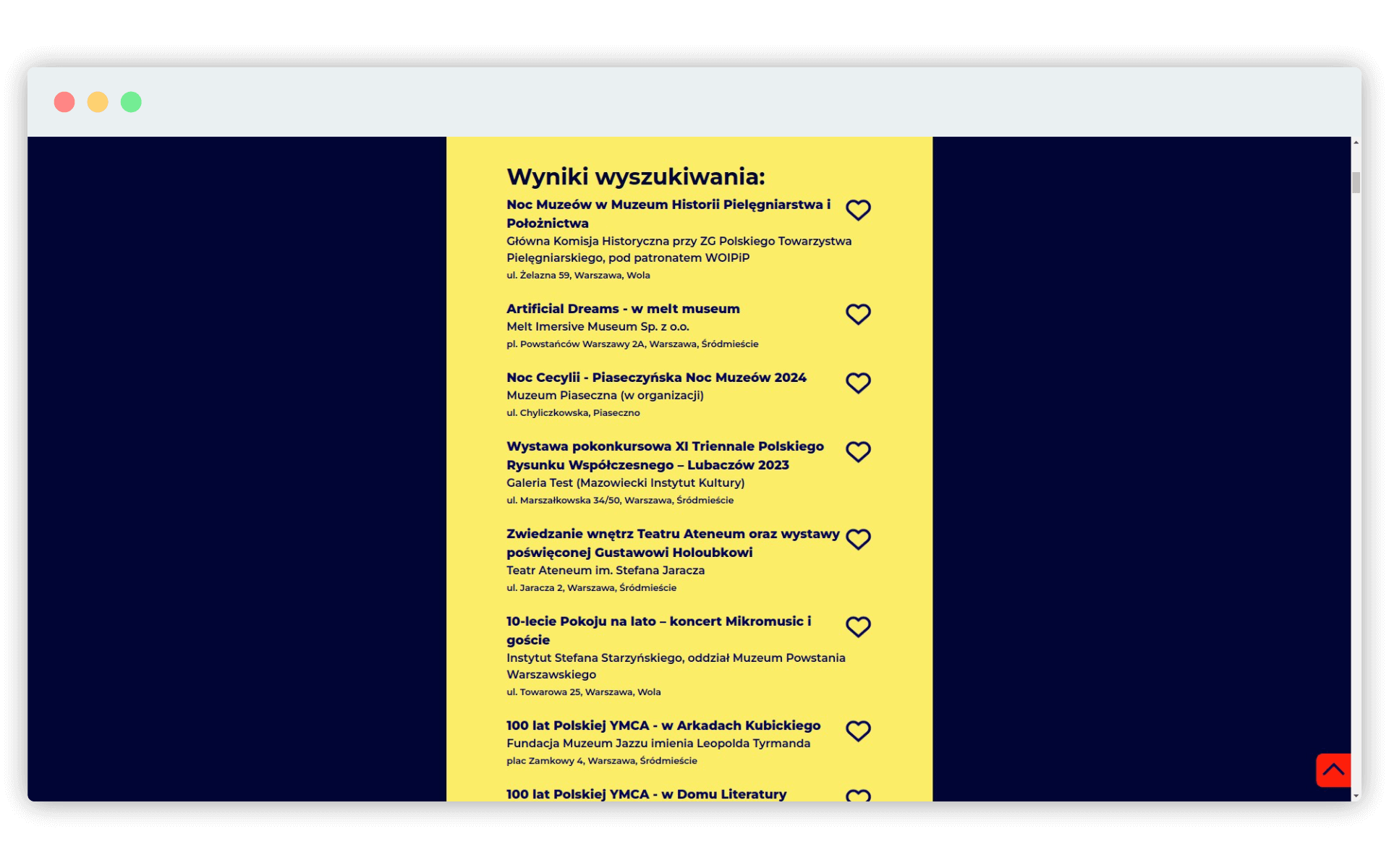
Niestety, szybkie spojrzenie na kod źródłowy tej strony potwierdzi, że jej treść jest generowana dynamicznie w przeglądarce a nie na serwerze. Oznacza to, że jeśli spróbujemy pobrać ją bezpośrednio w R, nie otrzymamy interesujących nas danych (moglibyśmy to zrobić przeglądarką działającą w trybie niegraficznym, ale to już temat na inną lekcję). Dlatego po prostu wybierzmy w naszej przeglądarce opcję Zapisz stronę jako i zapiszmy ją jako pojedynczy plik html. Nasza przeglądarka wyrenderowała treść strony i dopiero w takiej postaci możemy ją pobrać na dysk, aby potem zaimportować plik do środowiska Posit.cloud.
Logujemy się do Posit.cloud, zakładamy nowy projekt. Aby zaimportować plik, wybieramy w prawym dolnym oknie opcję Upload.
Praca z DOM w R
Do pracy z DOM w R potrzebujemy biblioteki xml2. Skorzystamy z udostępnianych przez nią metod aby zamienić plik HTML na listę węzłów (obiektów) DOM oraz wykonać odpowiednią kwerendę XPath.
Zaczynamy od instalacji pakietu i wczytania go do środowiska:
install.packages("xml2")
library(xml2)Następnie importujemy plik źródłowy do obiektu source funkcją read_html. Funkcja ta pozwala na wczytywanie stron bezpośrednio z internetu (z adresu URL), jednak w naszym przypadku nie ma to sensu - potrzebujemy strony wyrenderowanej już w przeglądarce.
source <- read_html('noc_muzeow.html')Source to obiekt o klasie xml_document - możemy na nim wykonywać kwerendy XPath. Aby przygotować taką kwerendę, musimy zajrzeć do kodu źródłowego wyrenderowanej strony. Wyświetlamy ją sobie w przeglądarce, zaznaczamy wybrany adres i klikamy prawym przyciskiem myszy Zbadaj:
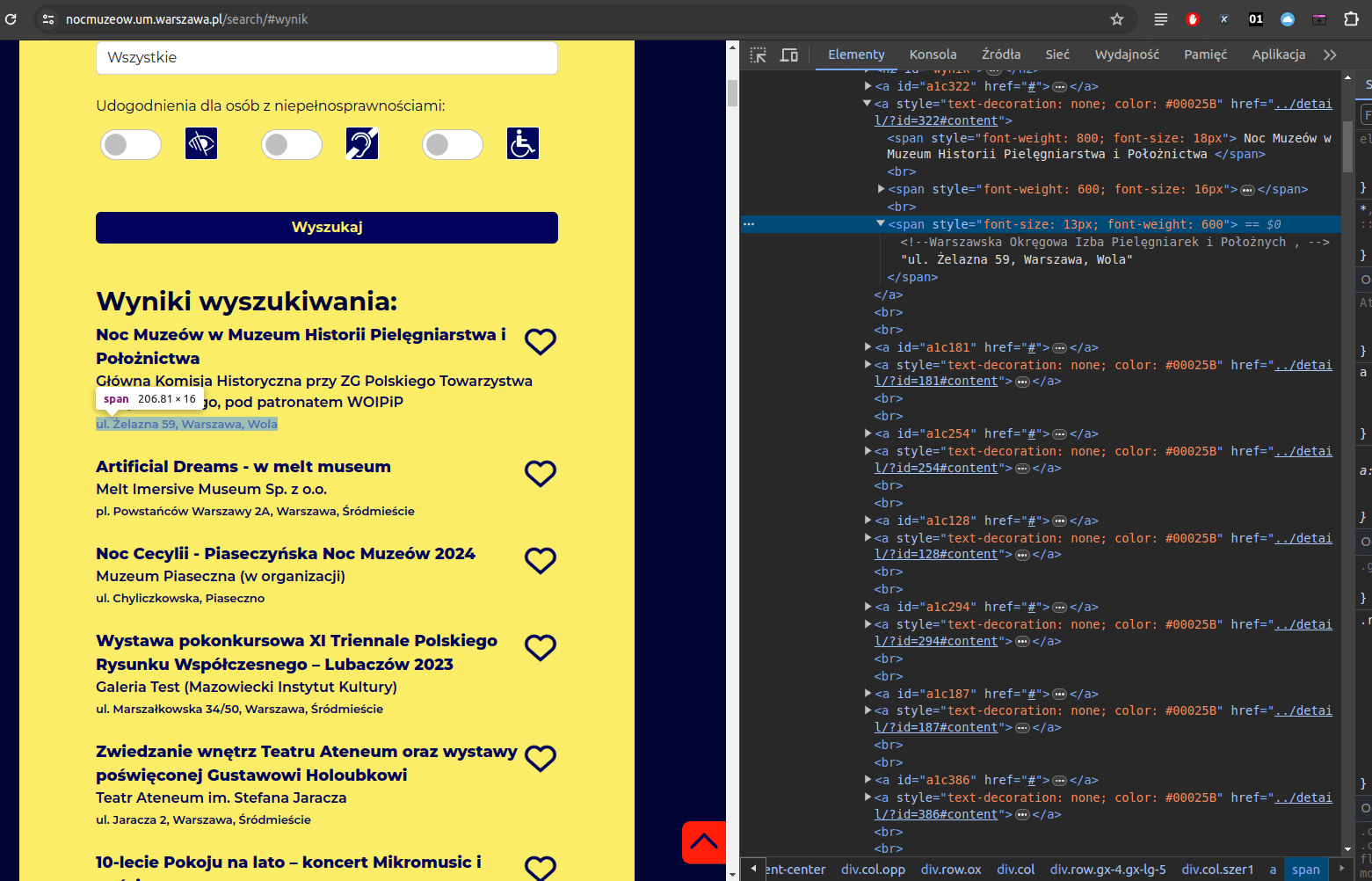
Adresy znajdują się w elemencie a i trzecim elemencie span:
<a style="text-decoration: none; color: #00025B" href="../detail/?id=322#content"><span style="font-weight: 800; font-size: 18px"> Noc Muzeów w Muzeum Historii Pielęgniarstwa i Położnictwa </span><br><span style="font-weight: 600; font-size: 16px">Główna Komisja Historyczna przy ZG Polskiego Towarzystwa Pielęgniarskiego, pod patronatem WOIPiP</span><br><span style="font-size: 13px; font-weight: 600"><!--Warszawska Okręgowa Izba Pielęgniarek i Położnych , -->ul. Żelazna 59, Warszawa, Wola</span></a>Dlatego kwerenda XPath przyjmie taką postać:
//a/span[3]/text()Oto wyjaśnienie kwerendy:
- // - operator podwójnego ukośnika wskazuje, że wyszukiwanie ma być rekursywne i dotyczyć całego dokumentu, bez względu na miejsce, w którym się znajduje. Kwerenda zaczyna wyszukiwanie od korzenia (root) dokumentu i przeszukuje wszystkie węzły potomne,
- a - ten fragment kwerendy wybiera wszystkie elementy a w dokumencie,
- /span[3] - ten fragment wskazuje, że kwerenda powinna uwzględniać wyłącznie trzeci element span, który jest bezpośrednio wewnątrz elementu a,
- /text() - ta część kwerendy wybiera tekst zawarty bezpośrednio w trzecim elemencie span - funkcja text() zwraca zawartość tekstową elementu.
W pakiecie xml2 dostępna jest metoda xml_find_all, za pomocą której możemy wysłać naszą kwerendę do obiektu source:
locations <- xml_find_all(source, "//a/span[3]/text()")Efektem tego kodu będzie lista węzłów (obiektów) DOM. To ważne, ponieważ w dalszej części pracy będziemy musieli ją odpowiednio przeformatować.
Adresy na koordynaty geograficzne
Problem, który musimy rozwiązać, polega na tym, że na stronie znajdują się wyłącznie adresy wydarzeń organizowanych w Warszawie w ramach Nocy Muzeum. Tymczasem do przygotowania mapy potrzebujemy koordynatów geograficznych (długość i szerokość geograficzna) - dzięki nim będziemy w stanie umieścić na mapie markery.
Mamy do przetworzenia ponad 300 adresów - nie ma sensu robić tego ręcznie. Skorzystajmy z wybranej usługi mapowania adresu do koordynatów. Popularnym rozwiązaniem jest udostępniany przez OpenStreetMap Nominatim - niestety, co sprawdziłem przygotowując lekcję, jakość jego pracy nie jest wystarczająca (wiele adresów nie zostało poprawnie rozpoznanych). Jedną z alternatyw jest skorzystanie z Arcgis. Pracujemy w R, więc możemy liczyć na pakiet, który ułatwi nam pracę z narzędziami do zamiany adresów na koordynaty geograficzne. Instalujemy pakiet tidygeocoder, aby móc skorzystać z wielu usług geolokalizacji adresów:
install.packages('tidygeocoder')
library(tidygeocoder)Większość usług geolokalizacji adresów jest płatna - mi dwukrotnie udało się skorzystać z Arcgis bez zakładania konta i autoryzacji, chociaż według dokumentacji jest ona wymagana.
Za pomocą usługi Arcgis będziemy odpytywać poszczególne adresy. Najpierw musimy zmienić obiekt locations z listy węzłów XML do zwykłego wieloelementowego wektora tekstowego:
locations = unlist(as_list(locations))Skorzystaliśmy z metody pakietu xml2 - as_list(), który przetwarza listę węzłów na listę zwykłych obiektów tekstowych, a następnie funkcją unlist() redukujemy listę do zwykłego wektora (obiektu) wieloelementowego.
Stwórzmy teraz pustą ramkę danych, do której wrzucimy pozyskane koordynaty.
map_data <- data.frame()Pętla for pozwoli nam pojedynczo wygenerować koordynaty dla każdego adresu w locations. Jako parametr funkcji geo() podajemy adres oraz metodę (arcgis) - to tutaj możemy swobodnie wybierać dostępne usługi lokalizacyjne. Sys.sleep() doda niezbędną pauzę po każdej iteracji - nie chcemy zostać odcięci od serwera usługi lokalizacyjnej. Funkcja rbind() dodaje do naszej ramki danych kolejne wiersze. Funkcja geo() zwraca ramkę danych, więc możemy to zrobić.
for(l in locations) {
map_data <- rbind(map_data, geo(address = l, method = "arcgis", mode = "single"))
Sys.sleep(1)
}Oto fragment pozyskanych danych:
| address | lat | long |
|---|---|---|
| al. Bohaterów Września 23, Warszawa, Ochota | 52.21531 | 20.95994 |
| al. Jana Pawła II 36, Warszawa, Śródmieście | 52.24080 | 20.99520 |
| Al. Jerozolimskie 107, Warszawa, Ochota | 52.22599 | 20.99484 |
| Al. Jerozolimskie 2, Warszawa, Śródmieście | 52.23292 | 21.02463 |
| Al. Jerozolimskie 3, Warszawa, Śródmieście | 52.23212 | 21.02420 |
| Al. Jerozolimskie 32, Warszawa, Śródmieście | 52.23148 | 21.01847 |
| Al. Jerozolimskie 51, Warszawa, Śródmieście | 52.22892 | 21.00854 |
| al. Komisji Edukacji Narodowej 61, Warszawa, Ursynów | 52.14903 | 21.04569 |
| al. Krakowska 61, Warszawa, Włochy | 52.17102 | 20.93544 |
markery i klastry w leaflet
Skoro mamy już dane, możemy zacząć pracę nad mapą - w pewnej części powtórzymy tu czynności znane z lekcji poświęconej podstawom budowania map w R. Zacznijmy od instalacji i uruchomienia pakietu:
install.packages("leaflet")
library(leaflet)Teraz możemy stworzyć mapę:
m <- leaflet(data = map_data) %>% addTiles() %>% addMarkers(~long, ~lat, popup = ~address, clusterOptions = markerClusterOptions())Ponieważ mamy na mapie ponad 300 punktów, skorzystaliśmy z funkcji markerClusterOptions(), aby wygenerować standardowe ustawienia do budowy klastrów. Klastry w Leaflet to zbiory markerów, które - na pewnym poziomie skali - rozwijają się w pojedyncze markery. Takie rozwiązanie zwiększa czytelność mapy.
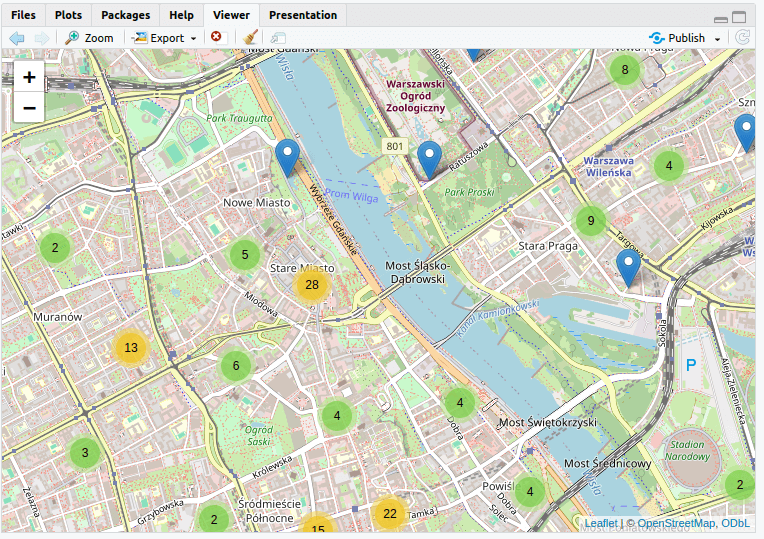
W ustawieniach klastrów możemy eksperymentować nie tylko z ich zachowaniem, ale też wyglądem:
markerClusterOptions(
showCoverageOnHover = TRUE,
zoomToBoundsOnClick = TRUE,
spiderfyOnMaxZoom = TRUE,
removeOutsideVisibleBounds = TRUE,
spiderLegPolylineOptions = list(weight = 1.5, color = "#222", opacity = 0.5),
freezeAtZoom = FALSE,
...
)Zmiana standardowej warstwy mapy
Na tej stronie zobaczyć możemy dostępne warstwy dla map zarządzanych przez Leaflet. Nie wszystkie udostępniane są przez OpenStreetMap. Łatwe skorzystanie z alternatywnych źródeł warstw kafelkowych (tiles) umożliwia pakiet leaflet.providers. Możemy też użyć tych warstw bezpośrednio za pomocą metody addProviderTiles() z pakietu leaflet.
Zmieńmy nasz kod, aby dodać nową warstwę. Uwaga: użycie niektórych warstw wymaga rejestracji konta na odpowiedniej stronie i uzyskania tokenu. W naszym przykładzie użyjemy warstwy Stadia.AlidadeSmoothDark.
m2 <- leaflet(data = map_data) %>% addProviderTiles(provider = "Stadia.AlidadeSmoothDark") %>% addMarkers(~long, ~lat, popup = ~address, clusterOptions = markerClusterOptions())Zwróćmy uwagę, że funkcja addTiles() nie jest już w tym przypadku potrzebna.
W efekcie zmienimy estetykę naszej mapy (w przypadku niektórych warstw możemy zmienić też informacje, jakie udostępnia nasza mapa):
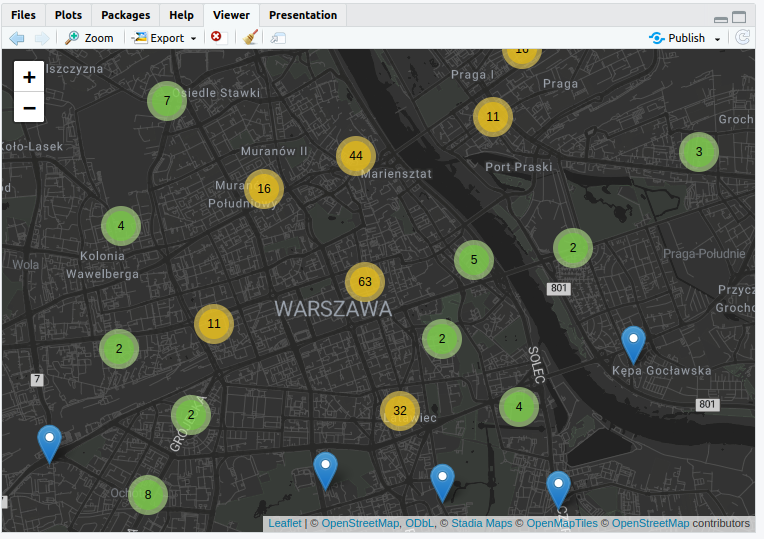
Możemy też przeprowadzić podstawową interpretację danych: wydarzenia organizowane w Warszawie w ramach Nocy Muzeów 2024 odbywały się przede wszystkim w centralnych dzielnicach na lewym brzegu:
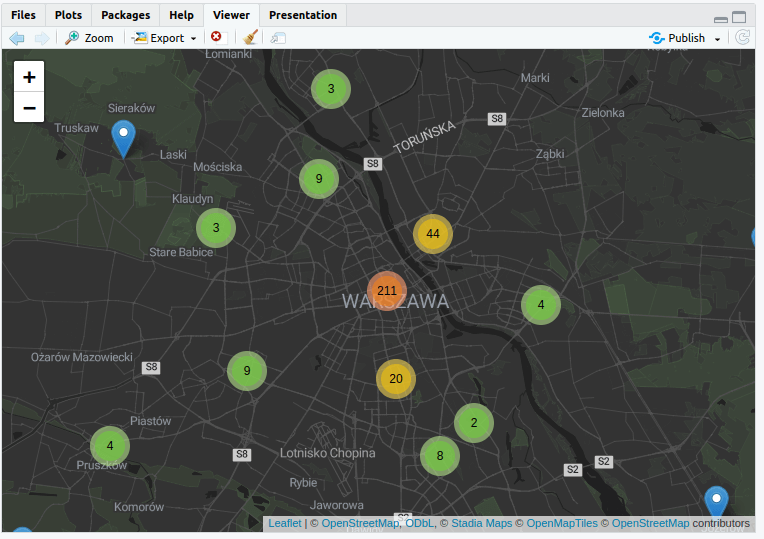
Mapę w działaniu zobaczyć można pod tym linkiem.
Podsumowanie
W ramach lekcji udało się nam przetworzyć adresy wydarzeń organizowanych w ramach Nocy Muzeów na punkty (markery) na mapie, a dzięki klastrom mogliśmy szybko odpowiedzieć na zadane na początku lekcji pytanie.
Wykorzystaliśmy dostępne źródło (stronę opublikowaną przez Urząd Miasta) i dzięki kwerendzie XPath wyodrębniliśmy z niej interesujące nas dane. Dzięki usłudze geolokalizacji adresów przygotowaliśmy dane do mapy i umieściliśmy je tam za pomocą metod biblioteki Leaflet. Tak przygotowaną mapę możemy umieścić online.
Wykorzystanie metod
Geolokalizacja adresów to przydatna usługa. Zamiast ręcznie wyszukiwać koordynaty poszczególnych punktów (zidentyfikowaliśmy ich ponad 370!), mogliśmy w kilka minut zebrać odpowiednie dane. Warto - pracując z danymi czy w ogóle praktykując cyfrowe metody - eksperymentować z rozwiązaniami maszynowymi. Dziś, dzięki ChatGPT i podobnym narzędziom, wydaje się to jeszcze prostsze. AI raczej nie zrewolucjonizuje ludzkiej twórczości, ale na pewno jest w stanie usprawnić wykonywanie powtarzalnych czynności. Nie zwalnia nas to jednak ze sprawdzenia jakości wyników, które maszynowo otrzymujemy, nawet jeśli jest to trudne ze względu na skalę.
Pomysł na warsztat
Lekcja jest kolejnym modułem do warsztatu z podstaw R.


