
Wprowadzenie
Efekt “żółtej Mleczarki” zwraca uwagę na jakość dostępnych online cyfrowych reprodukcji zbiorów dziedzictwa. W ramach tej lekcji zmierzymy różnice między dobrej i złej jakości cyfrowymi wizerunkami dzieła Vermeera. Ale jak można w ogóle mierzyć różnice między wizerunkami tego samego obrazu? Na przykład koncentrując się na kolorach i porównując ze sobą te dominujące w każdej z reprodukcji.
Cele lekcji
Celem lekcji jest praktyka pracy w środowisku R poprzez ćwiczenie z analizy kolorów z wykorzystaniem pakietu colordistance. Lekcja jest krótkim wprowadzeniem do teorii kolorów w obiektach cyfrowych, zwraca też uwagę na znaczenie udostępniania przez instytucje kultury i dziedzictwa dobrej jakości wizerunków obiektów ze swoich zbiorów.
Efekty
- podstawowa znajomość teorii kolorów i metod ich analizowania i przetwarzania,
- umiejętność posługiwania się narzędziami do analizy kolorów (palet) udostępnianymi przez pakiet colordistance,
- umiejętność interpretacji danych wizualizowanych w postaci osi 3D i histogramów,
- znajomość problemu “żółtej Mleczarki” w kontekście strategii udostępniania zbiorów przez instytucje GLAM (galerie, biblioteki, archiwa i muzea).
Efektem naszej pracy będzie mapa ciepła wizualizująca relacje między dominującymi kolorami ośmiu reprodukcji obrazu Vermeera, wygenerujemy ją jednak dopiero w części II. Teraz zajmiemy się podstawami pracy z kolorami w R i przygotujemy zestawy palet do porównywania.
Wymagania
Do skorzystania z lekcji konieczne jest zapoznanie się z wprowadzeniem do pracy z R w Posit.cloud oraz darmowe konto w tym systemie.
Dane do analizy znajdują się na GitHub.
Część merytoryczna
Lekcję zaczniemy od rozpoznania problemów, jakie w dostępie do dziedzictwa tworzy szeroki dostęp do reprodukcji cyfrowych o różnej jakości. Następnie przejdziemy do środowiska Posit.cloud, gdzie zaimportujemy pliki do analizy i wygenerujemy wizualizacje palet poszczególnych reprodukcji.
Problem “żółtej Mleczarki”
Instytucje dziedzictwa od lat digitalizują swoje zbiory i umieszczają je w internecie - jednak nie tylko one to robią. Jeśli obiekt z kolekcji muzeum jest znany (bo to na przykład Mona Lisa), w sieci znaleźć się mogą tysiące jego cyfrowych kopii. Pomyślcie o tych wszystkich osobach, które koniecznie muszą fotografować dzieła podczas wizyty w muzeum, a potem umieszczają te fotografie w mediach społecznościowych. Pomyślcie też o dostępnych online skanach słabej jakości, wykonywanych przed laty, sprzętem, który dziś jest już przestarzały, albo reprodukcjach umieszczonych w wydanych już dawno, ale zdigitalizowanych i dostępnych online książkach, katalogach czy pracach naukowych.
Wyszukajcie w Google Images wizerunek dowolnego powszechnie znanego i podziwianego dzieła. Setki, tysiące reprodukcji, o różnej jakości, w różnych kolorach. Jak znaleźć reprodukcję, która najlepiej oddaje wizerunek oryginału? Skąd możemy wiedzieć, jak naprawdę wygląda oryginalne dzieło?
Na tym właśnie polega problem “żółtej Mleczarki”, oryginalnie opisany w kontekście internetowej dostępności znanego dzieła Jana Vermeera, przechowywanego w Rijksmuseum. Swego czasu pracownicy muzeum zidentyfikowali tysiące alternatywnych, upowszechnianych niezależnie reprodukcji tego obrazu, wśród których znajdowały się reprodukcje bardzo słabej jakości, fałszujące oryginalne kolory dzieła.

Konsekwencje problemu
Konsekwencje efektu “żółtej Mleczarki” są poważne:
- przez wielość łatwo dostępnych reprodukcji tak różnej jakości korzystamy tak naprawdę z różnych dzieł: nie ma jednej Mleczarki Vermeera,
- w efekcie w interpretacjach dzieła, także w pracach naukowych czy edukacji szkolnej, mogą pojawiać się poważne błędy,
- ostatecznie instytucja dziedzictwa udostępniająca oryginalną reprodukcję jest tylko jednym z wielu źródeł wizerunków dzieła, w żaden sposób nie promowanym przez wyszukiwarki,
- zaufanie do niej może zostać podważone: osoby kupujące kartki pocztowe w sklepiku Rijksmuseum krytykowały jakość wydrukowanej na nich reprodukcji Mleczarki, ponieważ znały ten obraz z fatalnej jakości wizerunków dostępnych online, przekłamujących oryginalne kolory.
Częściowym rozwiązaniem tych problemów było udostępnienie przez Rijksmuseum wysokiej, produkcyjnej jakości wizerunku dzieła Vermeera, dzięki czemu - po pewnym czasie - znalazł się on na szczycie wyników wyszukiwań Google Images. Problem “żółtej Mleczarki” jest mocno powiązany z mechanizmami dostępu do zbiorów cyfrowych dziedzictwa. Google Images indeksuje obiekty z milionów różnych źródeł, w żaden sposób nie preferując witryn instytucji GLAM, a użytkownicy są zainteresowani przede wszystkim szybkim dostępem do obrazu (pliku), bez względu na to, kto go udostępnia.
Efekt “żółtej Mleczarki” został opisany w 2011 roku. Dziś zyskuje dodatkowy kontekst: wobec gwałtownego zwiększenia dostępności narzędzi AI do generowania grafiki, wyniki wyszukiwania Google zalewają tworzone automatycznie obrazy udające historyczne dzieła. Problemem jest już nie tylko niska jakość reprodukcji cyfrowej oryginału, ale fałszowanie oryginału. Bez wdrożenia powszechnych standardów oznaczania wygenerowanych sztucznie obiektów (nad czym pracuje koalicja C2PA), tego typu zasoby będą coraz większym wyzwaniem dla oferty muzeów i innych instytucji publikujących zbiory online.
Import plików do Posit.cloud
Celem naszej pracy jest wygenerowanie wizualizacji relacji między reprodukcjami Mleczarki różnej jakości. Aby to zrobić, musimy umieścić w projekcie R w Posit.cloud pliki do analizy.
Pobieramy plik images.zip z repozytorium Humanistyka.dev na GitHubie. Import do Posit.cloud jest łatwy, jednak jeśli chcemy umieścić w środowisku R od razu wiele plików, musimy wysłać paczkę zip.
Logujemy się do Posit.cloud, zakładamy nowy projekt. W panelu edytora, w prawej dolnej części ekranu, znajduje się lista plików. Załóżmy tam nowy katalog images (kilkamy New Folder). Wchodzimy do niego i wybieramy opcję Upload. Wybieramy plik images.zip z dysku naszego komputera i wysyłamy do Posit.cloud. System automatycznie rozpakuje nasze pliki do wskazanego katalogu.
W paczce images.zip znajduje się dziewięć plików: osiem to reprodukcje Mleczarki Vermeera, plik 100.png jest plikiem referencyjnym. W naszej wizualizacji powinien być maksymalnie odległy od innych plików - dzięki niemu upewnimy się co do poprawności naszej analizy.
Do rozpoczęcia pracy w R musimy jeszcze zaimportować pakiet colordistance. Pakiet znajduje się w oficjalnym repozytorium CRAN (The Comprehensive R Archive Network), wystarczy więc podać te dwa polecenia:
install.packages("colordistance")
library(colordistance)Problemy w pracy z kolorami
Kolor to czasem niezwykle istotna informacja. W naturze może służyć do odstraszania drapieżników albo wyróżniać płcie i być podstawą wyboru partnera do kopulacji. W fotogrametrii kolor może informować o właściwościach analizowanego obszaru lub obiektu - wskazywać na ukształtowanie terenu i rodzaj szaty roślinnej, albo ujawniać wady izolacji budynku. W kulturze kolor może być elementem estetyki, symbolem czy wyrazem emocji - kiedyś korzystały z tego nowopowstające zakony, dziś firmy rozwijające własną identyfikację wizualną. Publikowane są czasopisma naukowe poświęcone teoriom koloru i praktyce jego badania.
Chociaż kolor ma tak duże znaczenie, masowe (ilościowe) porównywanie kolorów często sprawia trudności. Problemem są metody kategoryzacji - wypracowywanie automatycznych odpowiedzi na pytania takie jak jaki kolor dominuje na tym obrazie albo jak rozróżnić błękitny od niebieskiego.
Hannah Weller to badaczka i autorka pakietu colordistance, który oferuje metody maszynowej ekstrakcji palet kolorystycznych i ich porównywania. Pakiet ten został przygotowany oryginalnie dla analiz biologicznych (ubarwienie ryb żyjących na rafach koralowych), ale z powodzeniem możemy go zastosować także do zbiorów dziedzictwa. Zanim to jednak zrobimy, sprawdźmy, jakie metody pracy z kolorami proponuje.
Kolory na osi współrzędnych?
załóżmy, że znajdujesz trzy kwiaty - czerwony, pomarańczowy i niebieski. Na podstawie ich kolorów możesz śmiało stwierdzić, że kwiaty czerwony i pomarańczowy są bardziej podobne do siebie niż którykolwiek z nich do kwiatu niebieskiego. Ale co jeśli pomarańczowy kwiat ma niebieskie plamy? Oczywiście jest bardziej podobny do kwiatu niebieskiego niż jednolity pomarańczowy kwiat, ale o ile? A co jeśli niebieski kwiat ma także czerwone plamy? To, co było oczywistym porównaniem wcześniej, staje się bardziej kwestią subiektywnej oceny, jeśli całkowicie polegamy na ludzkiej klasyfikacji.
— pisze Weller na stronie wprowadzającej do pracy z pakietem. Biblioteka colordistance pozwala na kwantyfikowanie różnic między kolorowymi obiektami. Kwantyfikowanie to ilościowe ujmowanie zjawiska ujętego opisowo - zamiast próbować nazywać kolory albo opisywać relacje między nimi, możemy je po prostu policzyć. Ale jak to zrobić?
Z opracowania o cechach obiektów cyfrowych wiemy, że każdy z nich posiada numeryczną reprezentację. W perspektywie koloru oznacza to, że każdy piksel, składający się na przestrzeń obrazu, ma przypisaną określoną wartość w określonym przedziale, wyliczoną podczas skanowania czy fotografowania. Wartość ta wyznacza kolor - w systemie RGB bazuje na relacjach między czerwonym, zielonym i niebieskim. Dzięki syntezie addytywnej umożliwia to generowanie skończonej, ale wciąż olbrzymiej liczby kolorów - ponad 16 mln. Każdy kolor definiowany jest za pomocą trzech elementów (R,G,B) i wartości od 0 do 255. Poniżej przykład palety kolorów z wartościami RGB. Pierwszy kolor z naszej przykładowej palety ma następujące wartości: czerwony: 133, zielony: 255, niebieski: 158.

W pakiecie colordistance każdy piksel analizowanego obrazu jest traktowany jako punkt w przestrzeni trójwymiarowej o specjalnie zaprojektowanej skali. Przejdźmy do Posit.cloud i spróbujmy wygenerować sobie taką wizualizację na podstawie jednego z plików.
i7 <- plotPixels("images/7.png", n = "all", lower=NULL, upper=NULL)Funkcja plotPixels przyjmuje wiele argumentów. Najważniejsze z nich to ścieżka analizowanego pliku i liczba analizowanych pikseli (n) - jeśli nie podamy tej liczby, funkcja zwizualizuje wszystkie, co może być dość wymagające sprzętowo przy dużych plikach. Parametry lower i upper służą do wyznaczania koloru tła - z oczywistych względów nie będzie to nam teraz potrzebne.


Każde położenie piksela na osi 3D jest determinowane przez jego kolor, a sam punkt pozostaje w tym samym kolorze, w jakim był na oryginalnym obrazie. Jednak jak zrozumieć skalę tej wizualizacji? Poszczególne osie oznaczają wartość podstawowego koloru (czerwonego, zielonego i niebieskiego). Spójrzmy na nasz referencyjny obrazek 100.png i wygenerowaną dla niego wizualizację:


Na osi 3D widać tylko jeden punkt, chociaż obrazek jest dwukolorowy. Drugi punkt też tam się znajduje - to biały punkt, zasłaniający nieco oś w prawym górnym rogu. Żółty punkt reprezentuje kolor R:238,G:180,B:0. Wartość niebieskiego to 0 - widzimy to na osi. Wartość koloru czerwonego to 238. Na osi koloru czerwonego punkt leży blisko 1, ponieważ 238 to ponad 96 proc. z 255 - maksymalnej wartości dla koloru w modelu RGB. Wartość zielonego to 180, a więc około 70 roc. 255 (na osi 0.7).
Grupowanie pikseli
Analizowane obrazy mogą mieć różną liczbę pikseli. Aby móc je porównywać, należy te piksele pogrupować. Pakiet colordistance pozwala zrobić to na dwa sposoby: za pomocą histogramu lub za pomocą k-średnich - autorka pakietu zaleca stosowanie tego pierwszego rozwiązania.
Pakiet udostępnia funkcję getImageHist, ktora wygeneruje histogram kolorów analizowanego obrazka:
h7 <- getImageHist("images/7.png", n = FALSE, bins=c(2, 2, 2), lower=NULL, upper=NULL)Funkcja getImageHist przyjmuje kilka argumentów - warto zwrócić uwagę na bin. Definiuje on, na ile koszy (sześcianów wydzielonych z osi 3D) będzie branych pod uwagę. Im więcej, tym nasza analiza będzie bardziej dokładna, ale trudniej będzie porównywać ze sobą poszczególne pliki. W naszym przypadku dla każdego koloru podstawowego (RGB) wyodrębniamy po dwa zbiory kolorów (łącznie 8 zbiorów). Opcja n ustawiona na FALSE sprawi, że analizowane będą wszystkie piksele obrazka.
W efekcie otrzymujemy histogram z ośmioma kolorami (mamy osiem podzbiorów). Kolory słupków wybrane są na podstawie koloru będącego w centrum podzbioru. Na osi Y pokazane jest, jaka część wszystkich pikseli znajduje się w danym podzbiorze.

Być może łatwiej będzie to zrozumieć na przykładzie obrazka referencyjnego 100.png, zawierającego tylko dwa kolory:
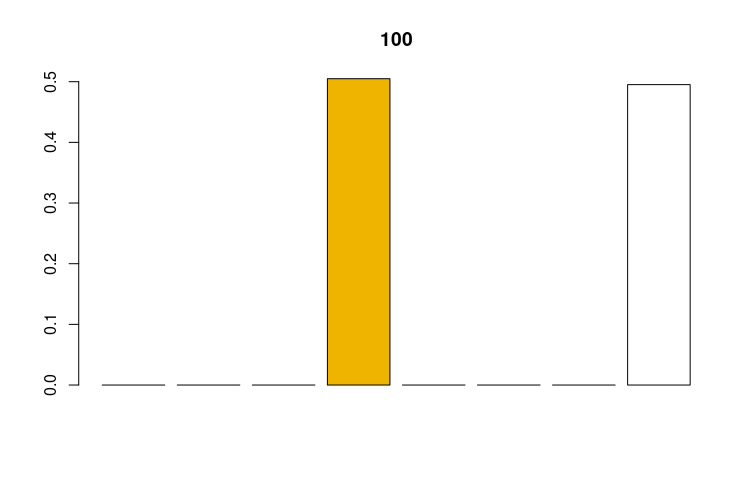
Generowanie palet dla wszystkich plików
Więcej na temat metody grupowania i jej ograniczeń przeczytać można w dokumentacji pakietu. Dzięki funkcji getHistList możemy wygenerować histogramy kolorów dla wszystkich analizowanych obrazków naraz. Najpierw wygenerujemy wektor ze ścieżkami do wszystkich plików funkcją dir:
images <- dir("images", full.names=TRUE)
> images
[1] "images/1.png" "images/100.png" "images/2.png" "images/3.png" "images/4.png" "images/5.png"
[7] "images/6.png" "images/7.png" "images/8.png" Następnie podamy obiekt images jako parametr funkcji getHistList:
getHistList(images, n = FALSE, bins=c(2, 2, 2), lower=NULL, upper=NULL, plotting=TRUE, pausing=FALSE)Wykresy poszczególnych palet zostaną wygenerowane i będzie można wyeksportować je do plików graficznych.
Interaktywna wizualizacja dominujących kolorów w zbiorze
Tę część pracy możemy podsumować, generując zbiorczą wizualizację dominujących kolorów w zbiorze naszych plików. W tym celu znów skorzystamy z funkcji getHistList, parametr plotting ustawimy jednak na FALSE.
cls <- getHistList(images, n = FALSE, bins=c(2, 2, 2), lower=NULL, upper=NULL, plotting=FALSE, pausing=FALSE)Obiekt cls zawiera listę skupień (clusters). Możemy podać go jako argument do funkcji plotClustersMulti.
clsViz <- plotClustersMulti(cls)Dzięki zastosowaniu biblioteki Plotly funkcja plotClustersMulti wygeneruje interaktywną wizualizację. Z pewnością będziemy jeszcze pracować z tą biblioteką, na razie warto zauważyć, że umożliwia ona nie tylko dynamiczne przeglądanie wizualizowanych danych, ale też eksportowanie plików graficznych z fragmentów wizualizacji czy podgląd wartości zmiennych. Wizualizację Plotly możemy też wyeksportować jako stronę internetową - używamy wtedy polecenia Export - Save as Web Page….
Na wykresie 3D widzimy dominujące w plikach naszego zbioru kolory - jest wśród nich też żółty kolor z obrazka referencyjnego. Po najechaniu myszą na punkt otrzymamy informację o tym, z jakiego pliku został wygenerowany oraz jego wartości dla poszczególnych kolorów podstawowych RGB.
Podsumowanie
Hannah Weller zaproponowała bardzo ciekawą metodę wyodrębniania palet kolorów z plików graficznych. Metoda, oryginalnie stosowana do badań biologicznych, może zostać z powodzeniem wykorzystana także w analizie zbiorów kultury. Pokazuje to, że do zastosowań humanistycznych możemy wykorzystywać narzędzia opracowywane i stosowane w dyscyplinach dalekich od humanistyki.
W ramach tej lekcji udało nam się wygenerować dane opisujące palety poszczególnych reprodukcji Mleczarki. Przed nami część II, w której poznamy metodę ich porównywania i wygenerujemy finalną wizualizację relacji między nimi.
Wykorzystanie metod
Maszynowa, ilościowa analiza koloru może być wykorzystana jako metoda czytania zdystansowanego. Ma ona też swoje analogowe pierwowzory, choćby dzieło Abrahama „Aby” Warburga (1866–1929) Atlas Mnemosyne:
Na kilkudziesięciu dużych, czarno-białych fotografiach utrwalono w nim zestawy wizualne składające się z reprodukcji ukazujących rozmaite dzieła sztuki, w całości lub we fragmentach, oraz ilustracje, ryciny i wycinki. Wszystkie te materiały w zaprojektowanych przez Warburga aranżacjach miały obrazować istotne przemiany rozmaitych pojęć symbolicznych w wyobraźni artystycznej i społecznej Europejczyków, ugruntowanej na tradycji antyku. Autor jednak nie zdążył opatrzyć ich komentarzem, chociaż wiadomo, że miał taki zamiar. Pozostawił jedynie kilka wstępnych szkiców, tytuły z ideami przewodnimi do poszczególnych zestawów i garść objaśnień do niektórych tablic. Uczeni opracowujący edycje atlasu zdołali zidentyfikować wszystkie umieszczone w nim przedstawienia. Jednak nikt nie wie, jak miała wyglądać zamyślana przez Warburga historia idei wizualnych, dla której miały one być podstawą.
Praktyczne wdrożenie ilościowej analizy koloru w badaniu tekstów kultury znajdziemy m.in. w pracy Images As Data: Cultural Analytics and Aby Warburg’s Mnemosyne (2016) i Methods and Advanced Tools for the Analysis of Film Colors in Digital Humanities (2020) oraz w projekcie Timeline of Historical Film Colors.
Pomysł na warsztat
Elementy lekcji można wykorzystać w trakcie warsztatu z podstaw pracy z R. Można też przygotować proste ćwiczenia z generowania palet z użyciem Colors.co. Odpowiednio ustawiając tę aplikację, można wyświetlać kody kolorów nie tylko w postaci szesnastkowej (np. #000000), ale też jako wartości RGB.
Niech uczestnicy warsztatu samodzielnie wygenerują własne palety, manipulując wartościami czerwieni, zieleni i koloru niebieskiego, a następnie zwizualizują je na trójwymiarowej osi. Planując warsztaty można skorzystać także z tego narzędzia pozwalającego na wygenerowanie wizualizacji 3D palety kolorów dowolnego obrazka.



.jpg){kind=link}