
Wprowadzenie
Media społecznościowe są ważną przestrzenią, w której instytucje kultury informują o swojej działalności, promują własne zbiory i wchodzą w bezpośredni dialog z odbiorcami. Badanie takiej przestrzeni może być podstawą różnorodnych analiz: strategii marketingowych, sposobów korzystania z zasobów cyfrowych czy języka mówienia o sztuce czy dziedzictwie. Media społecznościowe to także publiczny kanał wyrażania ocen i niekiedy skrajnych emocji - to wartościowe źródło, pozwalające zobaczyć, jak deklarowana misja instytucji zderza się z oczekiwaniami odbiorców. Jednak, aby skorzystać z tego źródła, trzeba mieć do niego dostęp - niestety, od kilku lat media społecznościowe coraz bardziej ograniczają możliwość swobodnego pozyskiwania zarządzanych przez siebie danych.
Cele lekcji
Celem tej lekcji będzie pozyskanie i podstawowa interpretacja danych o wpisach z facebookowego profilu Muzeum Narodowego w Warszawie. Zamiast samodzielnie łączyć się z API Facebooka (co jest trudne), skorzystamy z gotowego rozwiązania - platformy Apify.

Efekty
Efektem lekcji będą dane pozyskane z profilu facebookowego Muzeum Narodowego w Warszawie w postaci plików JSON i CSV. Przygotujemy też proste statystyki, żeby odkryć pewną wadę pobranych danych.
Wymagania
Aby pobrać dane, potrzebujemy darmowego konta w platformie Apify. Usługi dostępne w Apify są płatne, ale po założeniu konta mamy możliwość przetestowania możliwości tej platformy. Skorzystamy z takiej opcji do pobrania interesujących nas danych z Facebooka. Podczas rejestracji w Apify nie jest wymagane podawanie danych karty kredytowej. Dd wyliczenia statystyk i wygenerowania wykresu skorzystamy z języka R i platformy Posit.cloud, chociaż równie dobrze sprawdziłby się zwykły Excel czy Google Sheets.
Część merytoryczna
W 2018 roku wybuchła afera Cambridge Analytica: firma zebrała - bez ich zgody - dane 87 mln użytkowników Facebooka. Dane użyto potem do wspierania kampanii wyborczych republikańskich polityków - Teda Cruza i Donalda Trumpa. Jedną z konsekwencji afery Cambridge Analytica było to, że platformy społecznościowe zaczęły ograniczać dostęp do swoich danych. Wcześniej pozyskiwanie ich było relatywnie łatwe poprzez oficjalne intrfejsy programistyczne (API).
Apikalipsa
Proces zamykania dostępu do danych mediów społecznościowych określany jest czasem jako APIkalipsa (APIcalypse). Australijski badacz Axel Bruns w opracowaniu wskazuje na jej najważniejsze konsekwencje. Zamknięcie dostępu do danych
miało to szczególnie krytyczny wpływ na zdolność badaczy mediów społecznościowych do analizowania zjawisk takich jak przemoc online, mowa nienawiści, trolling i kampanie dezinformacyjne, a także do pociągnięcia platform do odpowiedzialności za rolę, jaką ich funkcje i polityki mogą odgrywać w ułatwianiu takich dysfunkcji [..] działania właścicieli platform, podejmowane w odpowiedzi na skandal Cambridge Analytica, budzą podejrzenia, że wykorzystano go, by aktywnie utrudniać krytyczną, niezależną, prospołeczną kontrolę prowadzoną przez naukowców.
Wraz z negatywnymi zmianami w API przestawało działać oprogramowanie, które tworzono na uczelniach do wsparcia pobierania danych do badań naukowych. Równolegle platformy - o czym pisze Bruns - samodzielnie wybierały badaczy i projekty, którym udostępniały wybrane zestawy danych. Część badaczy zainteresowała się alternatywnymi źródłami danych społecznych, porzucając dominujące platformy - w ten sposób polityka platform wprost wpłynęła na niezależność badań. Ci, którzy wciąż chcieli badać Facebooka czy Twittera, musieli sięgnąć po nowe metody. Wszystkie one bazowały na scrapingu danych.
Web scraping
O tym, czym jest web scraping, dowiedzieliśmy się już w jednej z pierwszych lekcji na humanistyka.dev. Przypomnijmy tylko, że web scraping to proces automatycznego pozyskiwania danych z witryn internetowych (a więc i platform mediów społecznościowych) za pomocą skryptów lub botów, które odwiedzają poszczególne strony i wyodrębniają z nich określone informacje. Jak pisze Bruns, próby takiego niezależnego pozyskiwania danych są dziś częścią rywalizacji między badaczami a dostawcami treści (właścicielami platform): powstają coraz to nowe narzędzia i, w odpowiedzi na nie, coraz to nowe metody ich blokowania.
Apify to zbudowana w Czechach platforma, która hostuje, rozwija i umożliwia budowanie własnych scraperów. Z Apify korzystają takie firmy jak Siemens, Intercom, Microsoft czy T-Mobile. Web scraping nie jest więc jedynie domeną badań naukowych i ma też duże znaczenie komercyjne.
Jednak czy takie scrapowanie jest legalne? Apify przekonuje, że tak, powołując się m.in. na regulacje unijne, ale równolegle podkreśla konieczność dbania o zasady ochrony danych osobowych i prawa autorskie. W naszym małym projekcie pobierać będziemy publiczne dane finansowanej z budżetu państwa instytucji kultury - scrapujemy wpisy, a nie komentarze, co ma też duże znaczenie wobec zasad RODO. Scrapowanie w ramach projektów badawczych ma też z pewnością inny status - warto skonsultować to na swojej uczelni.
Założenie konta i wybór aktora
Wchodzimy na Apify.com i zakładamy konto. Po potwierdzeniu maila i zalogowaniu się, wybieramy przycisk Go to Console (w prawym górnym rogu strony). Konsola to nasz obszar roboczy. Przejdźmy do zakładki Actors - to katalog scraperów, z których możemy skorzystać w ramach systemu Apify.
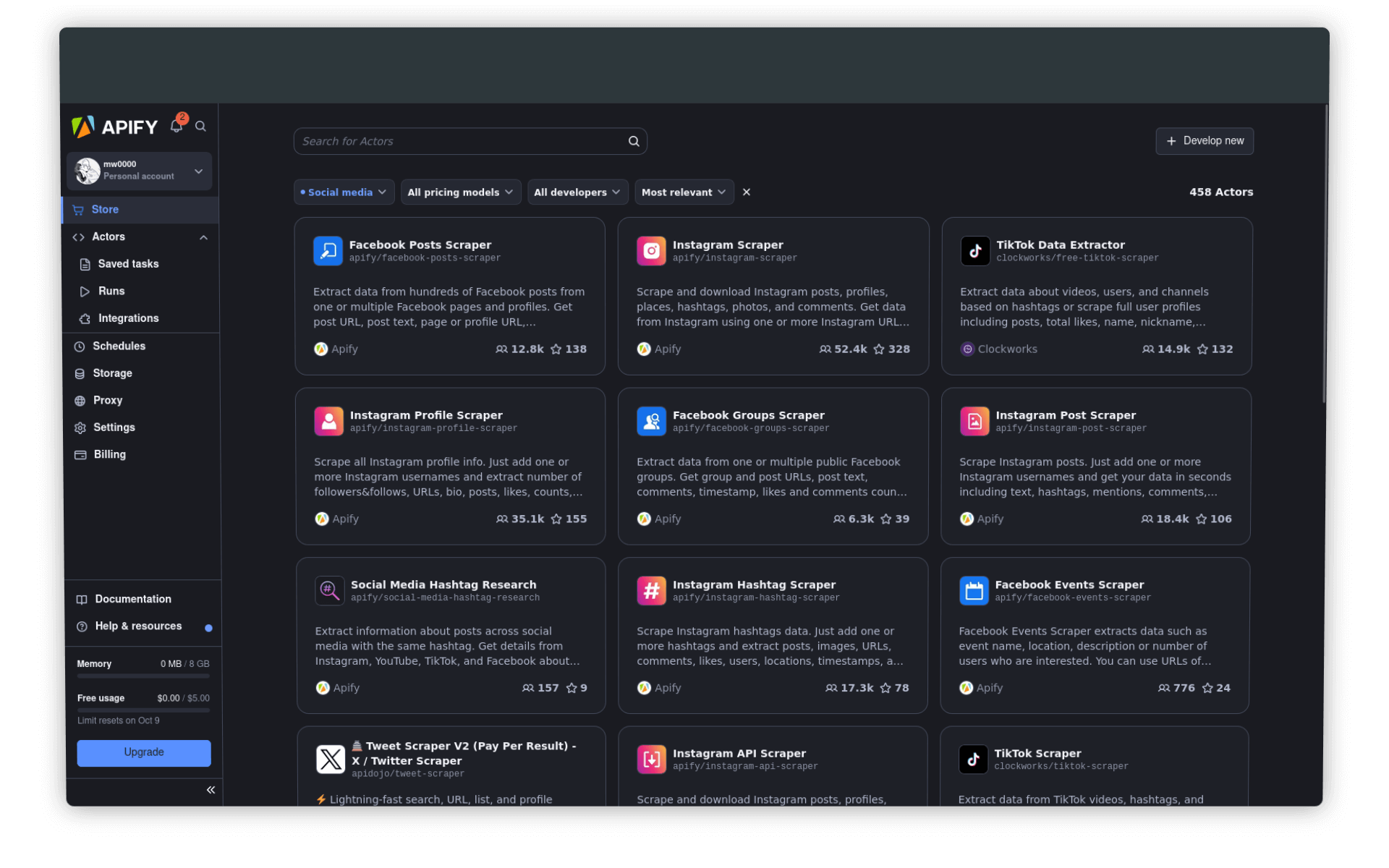
Czym są aktorzy (actors)?
Aktorzy to bezserwerowe (serverless) programy działające w chmurze. Mogą wykonywać różne zadania, od prostych czynności (takich jak wypełnianie formularza internetowego czy wysyłanie e-maila) po złożone operacje (takie jak przeszukiwanie całej strony internetowej czy usuwanie duplikatów z dużego zbioru danych). Aktorzy mogą działać tak krótko lub długo, jak jest to potrzebne – sekundy, godziny, a nawet bez przerwy.
Każdy aktor to kod źródłowy, niezbędne biblioteki i konfiguracja, zapisana jako obraz Dockera - można je porównać do płyt CD z zapisaną grą albo systemem operacyjnym. Z możliwości dowolnego aktora będziemy mogli skorzystać dopiero jeśli aktywujemy go w infrastrukturze Apify - można to zrobić bezpośrednio na stronie, przez terminal lub API. Część aktorów jest darmowych, część płatnych, płacić musimy jednak za sam proces gromadzenia danych. Na szczęście w ramach limitu darmowego konta jesteśmy w stanie przeprowadzić podstawowe próby scrapowania.
Będziemy pozyskiwać dane (wpisy) z profilu Muzeum Narodowego w Warszawie. Wykorzystamy dedykowany scraper, który jest w stanie pozyskać do 5 tys. postów z jednej strony (profilu). Koszt użycia tego aktora zależy oczywiście od ilości danych, jakie uda nam się pozyskać. Jeśli w trakcie pracy przekroczymi limit środków, które otrzymaliśmy po założeniu konta, scraper po prostu się zatrzyma i będziemy mieli do dyspozycji tylko część danych. Dla naszych celów to zdecydowanie wystarczy.
Warto podkreślić, że w żadnym razie nie włamujemy się do Facebooka ani nie pobieramy nieautoryzowanych danych z profilu Muzeum: pozyskamy tylko te wpisy i dane, które są publicznie dostępne.
Ustawienia i uruchomienie aktora
Po wyborze aktora powinniśmy zdefiniować podstawowe ustawienia scrapera. Kluczowy jest oczywiście adres interesującego nas profilu:
https://www.facebook.com/MuzeumNarodoweNależy podać też zakładaną liczbę powstów (wpisów), ewentualnie ustawić graniczne daty wpisów.
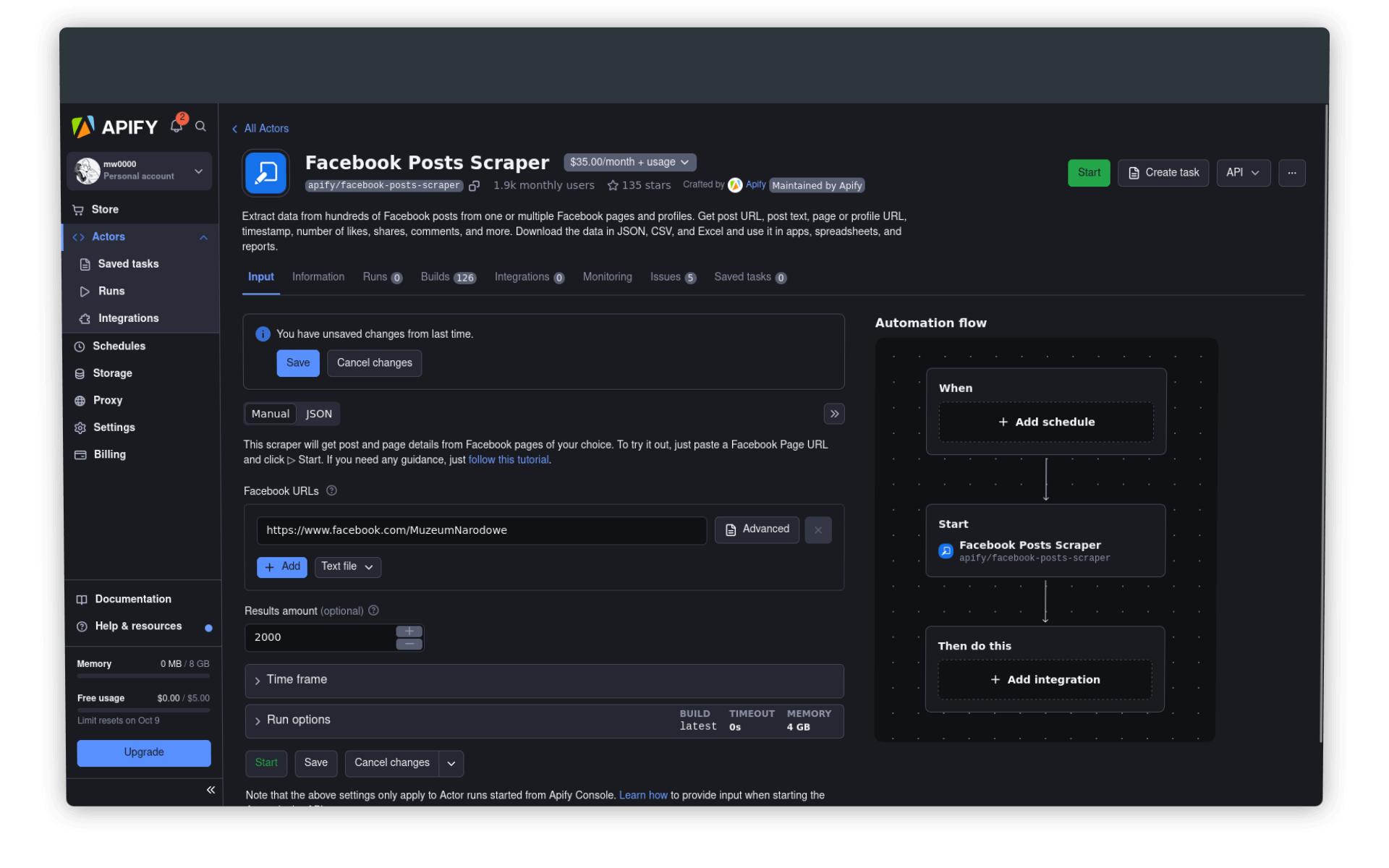
Po wypełnieniu odpowiednich pól klikamy na przycisk Start. Na stronie pojawią się informacje o przebiergu procesu, m.in. liczba wysłanych rządań (requests), bieżący koszt czy czas działania programu. Niżej, w zakładce Output, będziemy mogli na bieżąco podglądać spływające dane:
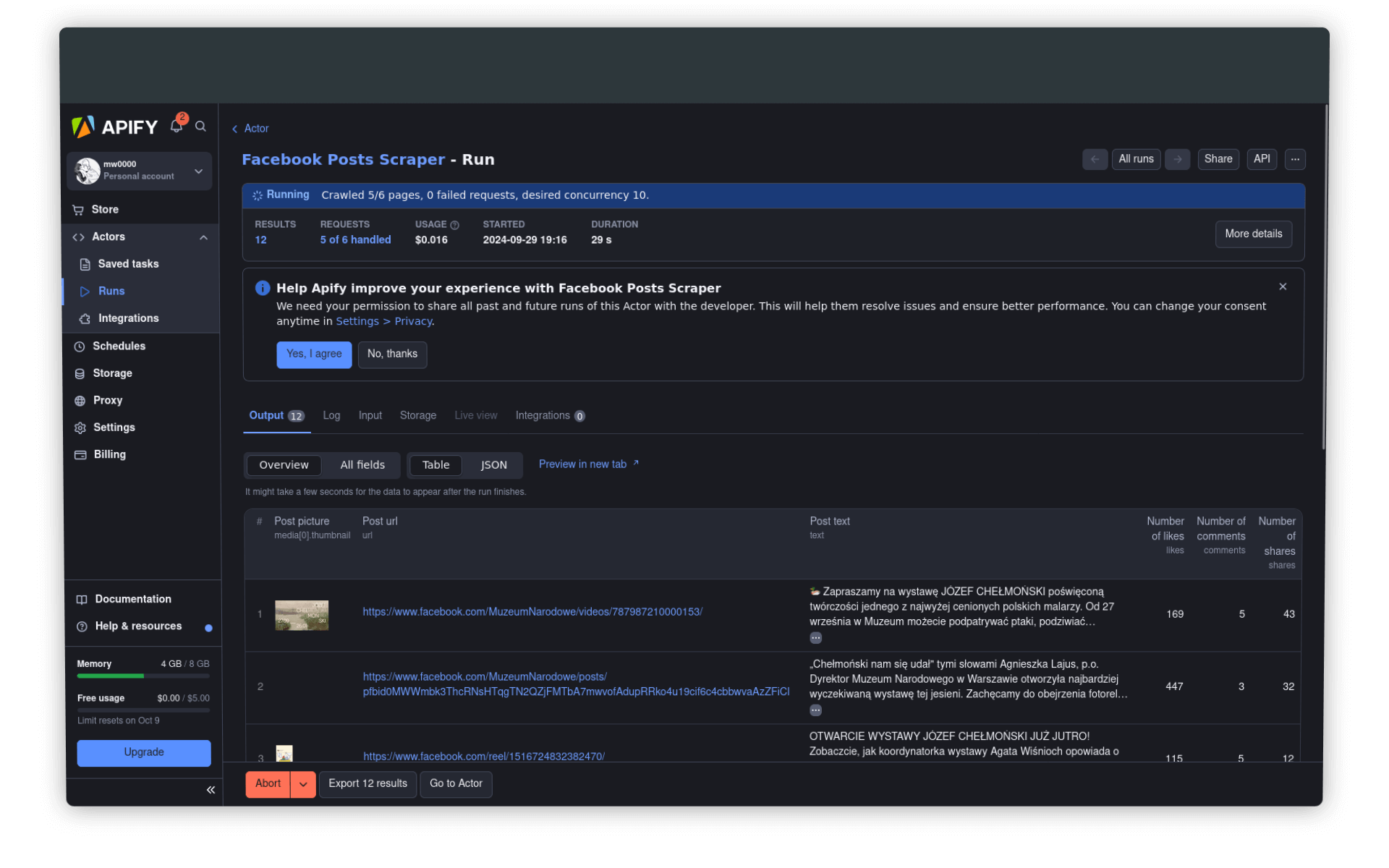
Zwróćmy też uwagę na zielone paski w lewym dolnym rogu aplikacji: tutaj wyświetlana jest informacja o zużyciu mocy obliczeniowej oraz bieżącym koszcie operacji i dostępnych środkach.
Podgląd i pobieranie danych
Jeśli uruchomiliśmy już scraper, możemy bezpiecznie wyłączyć komputer i wrócić do Apify w ciągu 1.5h - tyle czasu zajęło mi pobranie około 1700 wpisów - na więcej nie starczyło już darmowych zasobów (które mają odnowić się za kilka dni 😅).
Dane możemy pobrać w standardowych formatach dla danych: JSON, CSV, XML czy nawet tabela HTML lub plik Excela. Brzmi to bardzo obiecująco, ale warto zwrócić uwagę na pewien problem: pozyskane dane to nie tylko treści wpisów, ale bogaty zestaw metadanych, z których korzysta Facebook do generowania swojego interfejsu i publikowania w nim treści. Eksport takich pełnych danych do CSV czy Excela wygeneruje nam tablicę z ponad 800 kolumnami! Dlatego lepiej skorzystać z możliwości wyboru kolumn, których wartości chcielibyśmy wyeksportować:
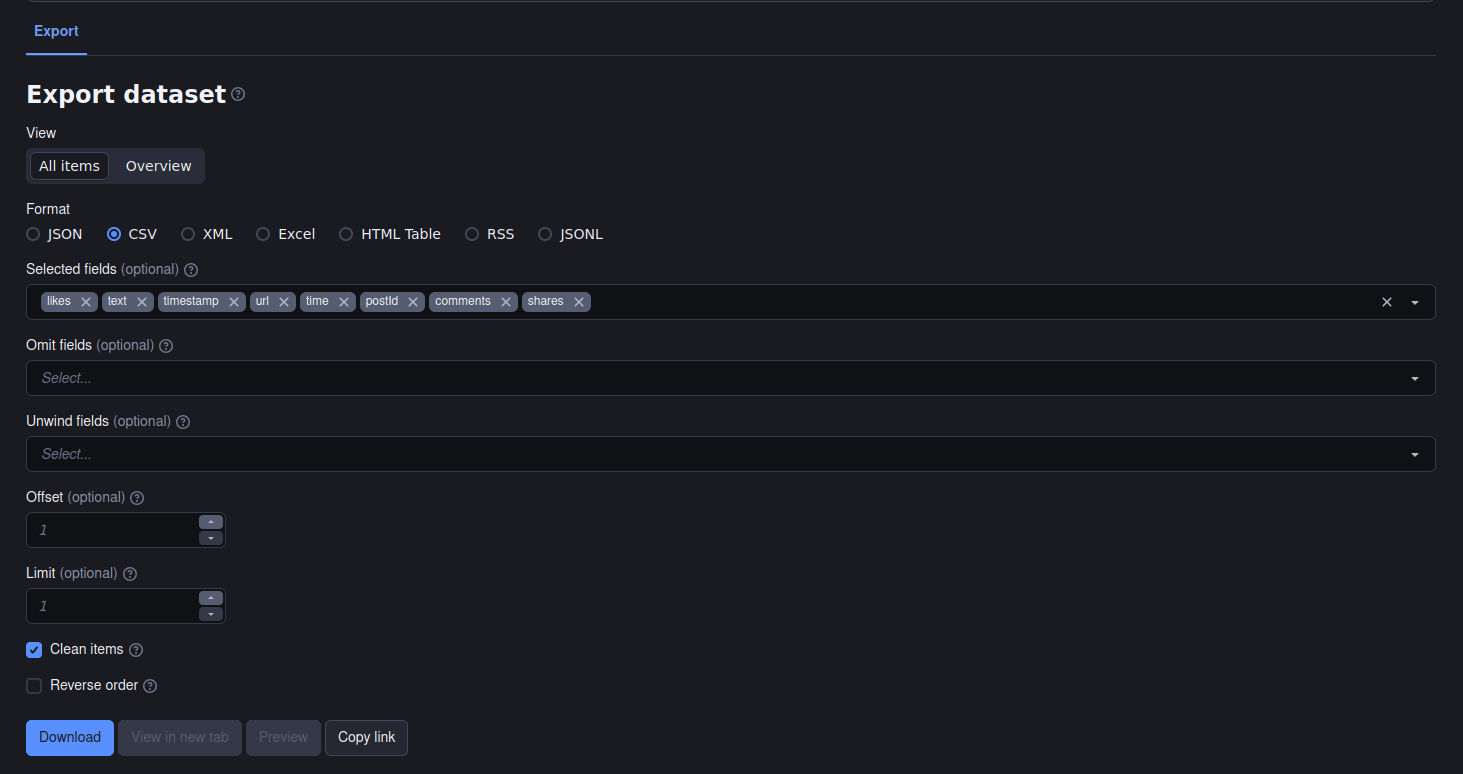
Zgromadzone zestawy danych znajdziemy w zakładce Storage: kluczowe jest nadanie im nazw, ponieważ nienazwane zestawy danych Apify usuwa po około tygodniu.
Proste statystyki i niemiła niespodzianka
Format JSON nadaje się najlepiej do sprawdzenia, jak bogaty zestaw metadanych pozyskaliśmy razem z treścią każdego wpisu:
{
"facebookUrl": "https://www.facebook.com/MuzeumNarodowe",
"postId": "4281278031883479",
"pageName": "MuzeumNarodowe",
"url": "https://www.facebook.com/MuzeumNarodowe/posts/pfbid02fHEm3JLEDkuvswUW9pLwYDUetMxhRhx9PLfDSZiWM8Ru6oe53e3cM57sdvNre75wl",
"time": "2021-03-21T14:55:16.000Z",
"timestamp": 1616338516,
"user": {
"id": "100064874070383",
"name": "Muzeum Narodowe w Warszawie",
"profileUrl": "https://www.facebook.com/MuzeumNarodowe",
"profilePic": "https://scontent.fdti1-1.fna.fbcdn.net/v/t39.30808-1/347842691_1028265664812302_5969893830851097948_n.jpg?stp=cp0_dst-jpg_s40x40&_nc_cat=102&ccb=1-7&_nc_sid=f4b9fd&_nc_ohc=LohIUdHvfqgQ7kNvgEdSw2k&_nc_ht=scontent.fdti1-1.fna&_nc_gid=A6-Cd5ez6fThWiuIrOc_Nz0&oh=00_AYBiKig8Gt1-9tcnzZQ7l-2w3aLjZjRzY_iGPhGmObySjw&oe=66FF8318"
},
"text": "#MNWiosna 🌷\n\nChoć warszawska pogoda na to nie wskazuje, dzisiaj przypada pierwszy dzień wiosny! W tym roku najbardziej adekwatnym obrazem na tę okazję wydaję się być „Przebudzenie wiosny\" polsko-szwajcarskiej malarki Anny Berent. \n\n🌳 Jak pogoda ulegnie poprawie, nie ma lepszego miejsca, żeby świętować nadejście wiosny, niż parki! Zachęcamy do spacerów (z zachowaniem odpowiednich środków bezpieczeństwa) w Królikarnia - Oddział Muzeum Narodowego w Warszawie oraz Muzeum w Nieborowie i Arkadii, Oddział Muzeum Narodowego w Warszawie. \n\n___\n\nZobacz „Przebudzenie wiosny\" w Cyfrowym MNW: 🔗 https://bit.ly/3c7O5wp",
"link": "https://bit.ly/3c7O5wp",
"likes": 185,
"comments": 3,
"shares": 14,
"media": [
{
"thumbnail": "https://scontent.fdti1-1.fna.fbcdn.net/v/t1.6435-9/163867053_4281276361883646_6940343697149893902_n.jpg?stp=dst-jpg_p180x540&_nc_cat=111&ccb=1-7&_nc_sid=13d280&_nc_ohc=hQwXNtGgZ44Q7kNvgGB9GF1&_nc_ht=scontent.fdti1-1.fna&_nc_gid=A6-Cd5ez6fThWiuIrOc_Nz0&oh=00_AYBtMal6hi-B1fuvkDjrMOqStSSMb0OJWPR7jlVfDoic_g&oe=67212315",
"__typename": "Photo",
"photo_image": {
"uri": "https://scontent.fdti1-1.fna.fbcdn.net/v/t1.6435-9/163867053_4281276361883646_6940343697149893902_n.jpg?stp=dst-jpg_p180x540&_nc_cat=111&ccb=1-7&_nc_sid=13d280&_nc_ohc=hQwXNtGgZ44Q7kNvgGB9GF1&_nc_ht=scontent.fdti1-1.fna&_nc_gid=A6-Cd5ez6fThWiuIrOc_Nz0&oh=00_AYBtMal6hi-B1fuvkDjrMOqStSSMb0OJWPR7jlVfDoic_g&oe=67212315",
"height": 540,
"width": 780
},
"__isMedia": "Photo",
"accent_color": "FF90949C",
"photo_product_tags": [],
"url": "https://www.facebook.com/photo/?fbid=4281276355216980&set=a.166518540026136",
"id": "4281276355216980",
"ocrText": "No photo description available."
}
],
"feedbackId": "ZmVlZGJhY2s6NDI4MTI3ODAzMTg4MzQ3OQ==",
"topLevelUrl": "https://www.facebook.com/100064874070383/posts/4281278031883479",
"facebookId": "100064874070383",
"pageAdLibrary": {
"is_business_page_active": false,
"id": "134515693226421"
},
"inputUrl": "https://www.facebook.com/MuzeumNarodowe"
}Dostęp do danych warunkuje to, jaki kształt może mieć nasza analiza: czy chcemy przetwarzać i interpretować tylko teksty wpisów? A może badać, dlaczego niektóre z nich mają dużą, a inne małą liczbę polubień albo udostępnień? A może chcemy pobrać wszystkie publikowane na profilu grafiki i sprawdzić, jaka część z nich przedstawia zbiory Muzeum?
Format JSON to zestaw kluczy i wartości - rzut oka na klucze pozwala nam oszacować, z jakimi informacjami mamy do czynienia. Każdy klucz JSON może być zamieniony na kolumnę w CSV lub pliku Excela.
Aby wyliczyć podstawowe statystyki, skorzystamy z R i Posit.cloud - wielokrotnie już używaliśmy tego środowiska do pracy. Importujemy plik CSV do ramki danych i wyliczamy podstawowe miary:
m <- read.csv('muzeum_narodowe_sample.csv', fileEncoding = "UTF-8", row.names = FALSE)
mean(m$likes, na.rm = TRUE)
[1] 218.4818
median(m$likes, na.rm = TRUE)
[1] 91Średnia liczba polubień postów profilu Muzeum Narodowego w Warszawie w latach 2021-2024 to 218 (rekordowe liczby polubień sięgają nawet 5-7 tys.!). Możemy też sprawdzić, w jakich miesiącach roku publikowano najwięcej na tym profilu: w tym celu wartości kolumny time (takie jak 2024-04-27T10:08:25.000Z) przekształcimy do postaci RRRR-MM:
m$year_month <- as.POSIXct(m$time, format="%Y-%m-%dT%H:%M:%OSZ", tz="UTC")
m$year_month <- format(m$year_month, "%Y-%m")
p <- as.data.frame(table(m$year_month))
names(p) <- c("rok_miesiac","liczba_wpisow")Niestety zebrane dane nie dokumentują okresu pandemii. Z jej powodu Muzeum Narodowe w Warszawie zostało zamknięte w październiku 2020 roku i otwarto je dopiero w lutym 2021 roku - tymczasem najstarsze wpisy, do jakich udało się nam dotrzeć, pochodzą z marca 2021. Gdybyśmy zebrali więcej danych, być może udałoby się udokumentować wzrost znaczenia Facebooka w pandemicznej komunikacji z odbiorcami.
Spróbujmy wygenerować wykres pokazujący zmianę w liczbie wpisów w czasie:
library(ggplot2)
install.packages("ggplot2")
ggplot(p, aes(x = rok_miesiac, y = liczba_wpisow, group = 1)) +
geom_line(color = "skyblue", size = 1) +
labs(x = "Rok i miesiąc (YYYY-MM)", y = "Liczba wpisów", title = "Wpisy na profilu Muzeum Narodowego w Warszawie") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))W efekcie:

Dopiero teraz widać, że dane są niepełne 😢 (zwróćmy uwagę na okres od maja 2023 do lutego 2024). Czy to efekt tego, że scraper zatrzymał się przed zakończeniem pobierania i zakolejkowane do pozyskania wpisy nie zostały umieszczone w zbiorze danych? Trudno przecież wyobrazić sobie, że w tym czasie Muzeum nie publikowało nic na Facebooku…
Podsumowanie
Apify to obiecujące narzędzie, niestety niewolne od ograniczeń i wad. Jak pokazał wygenerowany przez nas wykres, otrzymaliśmy niepełne dane, które zaburzałyby interpretację w naszym projekcie badawczym. Zaletą Apify jest prostota - w ciągu 1.5h zebraliśmy informacje o 1700 wpisach z profilu Muzeum Narodowego, bez konieczności programowania i hostowania własnych scraperów. Dane dostępne są w wygodnych formatach, można też łatwo zarządzać eksportem i wybierać tylko interesujące kolumny (klucze).
Czy przy pracy z zasobami instytucji kultury w mediach społecznościowych jesteśmy skazani na narzędzia takie jak Apify? Niekoniecznie - korzystać można z płatnych rozwiązań do monitoringu mediów społecznościowych lub… wypróbować dostęp do danych przez wnioski o udostępnienie informacji publicznej.
Wykorzystanie metod
Apify wydaje się użytecznym narzędziem do łatwego pozyskiwania danych z mediów społecznościowych - odwołanie do tej platformy pojawia się już w abstraktach kilkudziesięciu artykułów naukowych. Przywoływany wyżej w kontekście APIkalipsy Axel Bruns zwraca jednak uwagę na duże ograniczenie metody web scrapingu w kontekście zasobów platform społecznościowych:
ponieważ platformy takie jak Facebook kształtują treści widziane przez użytkowników na podstawie tego, co ich algorytmy wydają się wiedzieć o zainteresowaniach użytkowników, treści pobierane z platformy będą zależne od tego, jak rozumie ona “fałszywego” użytkownika stworzonego przez badaczy, a nie od bardziej neutralnej selekcji treści dostarczanej przez API.
Z drugiej strony nawet korzystając z oficjalnego API platform nie możemy mieć pewności, na jakiej podstawie proponowane są nam określone dane - tak było m.in. w przypadku Twittera, który jeszcze do niedawna był przyjazną platformą dla badaczy i badaczek. W efekcie zapytań darmowego API można było uzyskać kilka proc. twittów z ogólnego streamu, nie było jednak wiadomo, w jaki sposób algorytm wybierał te, które miały znaleźć się w udostępnionych danych.
Pomysł na warsztat
Apify to narzędzie no-code, nie wymaga pracy programistycznej, dzięki czemu można użyć je na warsztatach wprowadzających do analizy danych z mediów społecznościowych. Ciekawym użyciem Apify mógłby być też warsztat, podczas którego uczestnicy starają się samodzielnie pobrać swoje dane z Facebooka (dane ze swoich profili) za pomocą jednego z aktorów. Sprawdzenie na własnym przykładzie, jak głęboko Facebook opisuje nasze konta i nasze interakcje z innymi może być cenne, choćby w kontekście rozwijania w sobie odpowiednio krytycznej postawy wobec udostępniania informacji o sobie w internecie.


