
Wprowadzenie
Być może wiele osób, które na fali powszechnego zainteresowania AI spróbowało pracy z darmową wersją ChatGPT, po pewnym czasie uznało, że korzystanie z tego narzędzia jest bezcelowe. Zawiedli się szczególnie ci, którzy oczekiwali szczegółowej wiedzy z niszowych dziedzin oraz specjalistycznych kompetencji. Nawet w wersji darmowej ChatGPT to potężne narzędzie, może nawet ułatwiać pracę programistyczną czy wykonywać proofreading w tekstach naukowych, ale nie jest w stanie pomóc w rozwiązywaniu bardzo specyficznych zadań. Co więcej, nawet jeśli wygeneruje odpowiedzi na zaawansowane pytania, istnieje duże niebezpieczeństwo, że będą one halucynowane.
Ograniczenia dużych modeli językowych (Large Language Models, LMM), takich jak GPT, wynikają z danych, na których są one trenowane. Modele takie w toku konwersacji z użytkownikiem czy użytkowniczką są w stanie odpowiedzieć wyłącznie na pytania w jakikolwiek sposób nawiązujące do treści, które zebrano, aby je przeszkolić.
Próbą obejścia tych ograniczeń jest technika Retrieval Augmented Generation (RAG). Zakłada ona, że duży model językowy będzie generował odpowiedzi lepszej jakości, jeśli udostępni mu się dodatkowe, zewnętrzne źródła (dokumenty, dane).
Cele lekcji
W ramach tej lekcji pracować będziemy z ogólnodostępnym (dla użytkowników Google) systemem RAG - aplikacją NotebookLM. Poznamy zalety i wady tego sposobu pracy z dużymi modelami językowymi.
Efekty
Bezpośrednim efektem naszej pracy będą informacje i wiedza, zebrane na podstawie jedenastu opracowań poświęconych działalności muzeów w czasie pandemii COVID-19 i z wykorzystaniem dużego modelu językowego Google - Gemini 1.5. Chcemy jednak przede wszystki przetestować to narzędzie i sprawdzić, jak radzi sobie z konkretnymi zadaniami, które mogą pojawić się podczas pracy badawczej.
Wymagania
Z NotebookLM pracujemy w przeglądarce. Konieczne jest posiadanie konta Google. Dane, które udostępnimy do systemu, zostały wcześniej zebrane i dostępne są na GitHub. Oczywiście w ramach ćwiczenia można dodawać także własne dane (opracowania, raporty, dokumenty). Google zapewnia, że
Usługa NotebookLM nie jest trenowana na podstawie Twoich danych osobowych, w tym przesłanych przez Ciebie źródeł, zapytań ani odpowiedzi modelu
ale z pewnością nie warto udostępniać tam prywatnych czy tym bardziej niepublicznych dokumentów instytucji, w których pracujemy.
Pracować będziemy wyłącznie z treściami tekstowymi, ale do zbioru źródeł NotebookLM można udostępnić także nagrania audio (np. w postaci mp3).
Część merytoryczna
Zanim zaczniemy pracę z NotebookLM, poznamy podstawy teoretyczne techniki RAG. Następnie zaimportujemy nasze pliki źródłowe do aplikacji i będziemy - w trakcie konwersacji z modelem - zlecać określone zadania, które odwoływać się będą do wiedzy w nich zawartej.
Ograniczenia generycznych modeli
Trudno sprawnie przetłumaczyć pojęcie Retrieval Augmented Generation, dlatego będę korzystał z propozycji Microsoftu, który RAG tłumaczy jako rozszerzoną generację (takie rozszerzenie możliwe jest oczywiście dzięki dodatkowym źródłom wiedzy dla modelu).
Jak działa RAG? Musimy mieć najpierw duży model językowy, taki jak GPT (nie mylić z ChatGPT, który jest po prostu jego aplikacją) czy Gemini. Model ten jest trenowany na olbrzymich zbiorach treści - to m.in. zasoby Wikipedii, archiwa projektu Common Crawl, gromadzącego treści miliardów stron internetowych czy zasoby platform społecznościowych, z którym wydawca modelu podpisał odpowiednie umowy.
Treści te mogą zawierać wiedzę, która byłaby użyteczna z punktu widzenia specjalisty czy specjalistki, ale wcale nie musi tak być. Czy w rozmowie z ChatGPT jesteśmy w stanie poznać najnowszy stan badań nad pochodzeniem Galla Anonima albo sprawdzić, jak przez ostatnią dekadę zmieniła się liczba księgarń w województwie śląskim? Czy na pewno możemy oczekiwać, że automatyczne tłumaczenie z łaciny średniowiecznej będzie poprawne albo w automatycznie wygenerowanej charakterystyce naszej instytucji pojawią się akurat te specjalistyczne pojęcia, na których nam zależy?
Generyczność (bycie ogólnym lub uniwersalnym) dużych modeli językowych to ich olbrzymie ograniczenie, jeśli zależy nam na wykorzystywaniu ich do zadań wymagających specyficznej wiedzy czy kompetencji. Czasem da się ją obejść za pomocą odpowiedniej inżynierii promptów: podawaniu kontekstu i przykładów czy tworzenia person. Zdecydowanie skuteczniejszym rozwiązaniem jest jednak RAG.
RAG: rozszerzona generacja
Skoro mamy już dostęp do generycznego dużego modelu językowego, możemy wykorzystać go do tego, aby pobierał i przetwarzał z zewnętrznych źródeł specjalistyczną wiedzę. Źródła te po załadowaniu do aplikacji umieszczane są - jak czytamy na stronach dokumentacji Microsoftu - w magazynie danych, przestrzeni, która dostępna jest dla modelu.
Gdy użytkownik zadaje pytanie, magazyn danych jest przeszukiwany na podstawie danych wejściowych użytkownika. Pytanie użytkownika jest następnie łączone z pasującymi wynikami i wysyłane do usługi LLM przy użyciu monitu [promptu] (jawne instrukcje dla modelu sztucznej inteligencji lub uczenia maszynowego) w celu wygenerowania żądanej odpowiedzi.
W technice RAG duży model językowy nie jest dotrenowywany udostępnianymi przez nas dokumentami (treściami), raczej jego możliwości wykorzystywane są do tego, aby pobrać określoną wiedzę z tych źródeł, przetworzyć ją i udostępnić jako odpowiedź w konwersacji z użytkownikiem.
Pamiętajmy, że w modelach językowych nie ma żadnej wiedzy a jedynie zestawy prawdopodobieństw pojawiania się kolejnych słów (tokenów) w odpowiedzi. W RAG dokumenty zewnętrzne także nie są źródłem wiedzy. Udostępnione przez nas treści zamieniane są na wektory, podobnie jak nasze zapytanie. W przestrzeni wektorowej następuje wyszukiwanie i zwrócone treści, po przekodowaniu na tekst, doklejane są do naszego promptu. Prompt wysyłany jest do modelu językowego, który na jego podstawie generuje odpowiedź w języku naturalnym. Uh 😅.
Udostępnianie dokumentów w NotebookLM
Pora na praktykę. Z GitHuba pobierzmy jedenaście plików zawierających raporty i opracowania dotyczące działalności muzeów w czasie pandemii COVID-19. Te materiały to:
- Michalina Petelska, Polskie muzea w czasie pandemii COVID-19: działalność online i (nie)stosowanie Rapid Response Collecting (2021),
- Alicja Dudzińska, Andżelika Gąsiorek, Muzea w czasie pandemii COVID-19: Przykłady Kelvingrove Art Gallery Museum, Gallery of Modern Art, Narodowego Muzeum w Krakowie oraz Muzeum Powstania Warszawskiego (2021),
- UNESCO, Museums around the world in the face of COVID-19 (2021),
- Magdalena Lewicka, Wpływ pandemii COVID-19 na działalność muzeów (2023),
- Network of European Museum Organisations, Survey on the impact of the COVID-19 situation on museums in Europe. Final Findings and Recommendations (2020),
- Network of European Museum Organisations, Survey on the impact of the COVID-19 situation on museums in Europe. Survey on the impact of the COVID-19 situation on museums in Europe. Final Report (2020),
- Katarzyna Szara, Zachowania pracowników muzeów w okresie COVID-19 w perspektywie ekonomii behawioralnej na przykładzie Muzeum Okręgowego w Rzeszowie (2024),
- Mateusz M. Bieczyński, Muzea w internecie w odpowiedzi na „kulturowy szok” pandemii COVID-19 (2023),
- opublikowane na Wikipedii hasło Pandemia COVID-19 w Polsce (wersja PDF),
- NIMOZ, Działalność muzeów w czasach pandemii COVID-19,
- ICOM, Museums, museum professionals and COVID-19.
Te opracowania to bardzo, bardzo dużo tekstu, z którym musimy sobie poradzić 😨. Nie zostały też zebrane w ramach dogłębnej analizy i w żadnym wypadku nie powinny być traktowane jako podstawa do badań naukowych. Potraktujmy je po prostu jako materiał ćwiczeniowy. Zwróćmy uwagę, że w tym zbiorze znajdują się teksty w dwóch językach, artykuły naukowe o bardzo tekstowej, minimalistycznej formie i raporty, które przygotowano w ramach profesjonalnego składu, zawierające tabele i grafiki. Zobaczymy, jak NotebookLM sobie poradzi z tak różną postacią treści.
Wchodzimy na stronę notebooklm.google.com, logujemy się i zakładamy nowy notatnik. Zostaniemy automatycznie przekierowani do formularza, za pomocą którego możemy uploadować nasze źródła do aplikacji. Oprócz dokumentów PDF możemy udostępnić pliki tekstowe, markdown i nagrania audio. NotebookLM poradzi sobie także z materiałami z YouTube i stronami WWW (możemy podać wybrane linki).
W trakcie pracy z aplikacją możemy dowolnie ograniczać zakres bazy źródłowej - jeśli chcemy, żeby odpowiedzi generowane były tylko na podstawie wybranych źródeł, odznacznmy inne z listy w lewym panelu okna. Kliknięcie w tytuł źródła pozwala podejrzeć jego treść w postaci tekstowej, co jest szczególnie użyteczne wobec tego, że nasze treści importowaliśmy w postaci plików PDF. W lewym górnym rogu możemy ustawić tytuł notatnika.
Jak pracować z NotebookLM?
NotebookLM nie wykona za nas podstawowej pracy związanej z zaplanowaniem tematu badania i jego metod (przynajmniej, jeśli chcemy, żeby było to badanie dobrej jakości). Korzystajmy z niego do przeszukiwania, streszczania i podstawowego wnioskowania z zebranych źródeł - to, jakie pytania i polecenia będziemy zadawać, wynikać musi z naszego pomysłu na analizę.
Podstawowym narzędziem NotebookLM jest notatka. Możemy stworzyć ją sami, wpisując cytat z interesującego nas opracowania lub pomysł na dodatkowe źródła. W trakcie pracy konwersujemy z modelem - generowane przez niego na podstawie źródeł odpowiedzi możemy dodatkowo wyeksportować do notatek. Kiedy stworzymy już wiele notatek, będziemy mogli zaznaczyć wybrane lub wszystkie, aby wygenerować podsumowanie, konspekt czy otrzymać sugestie co do dalszych tematów i wątków:
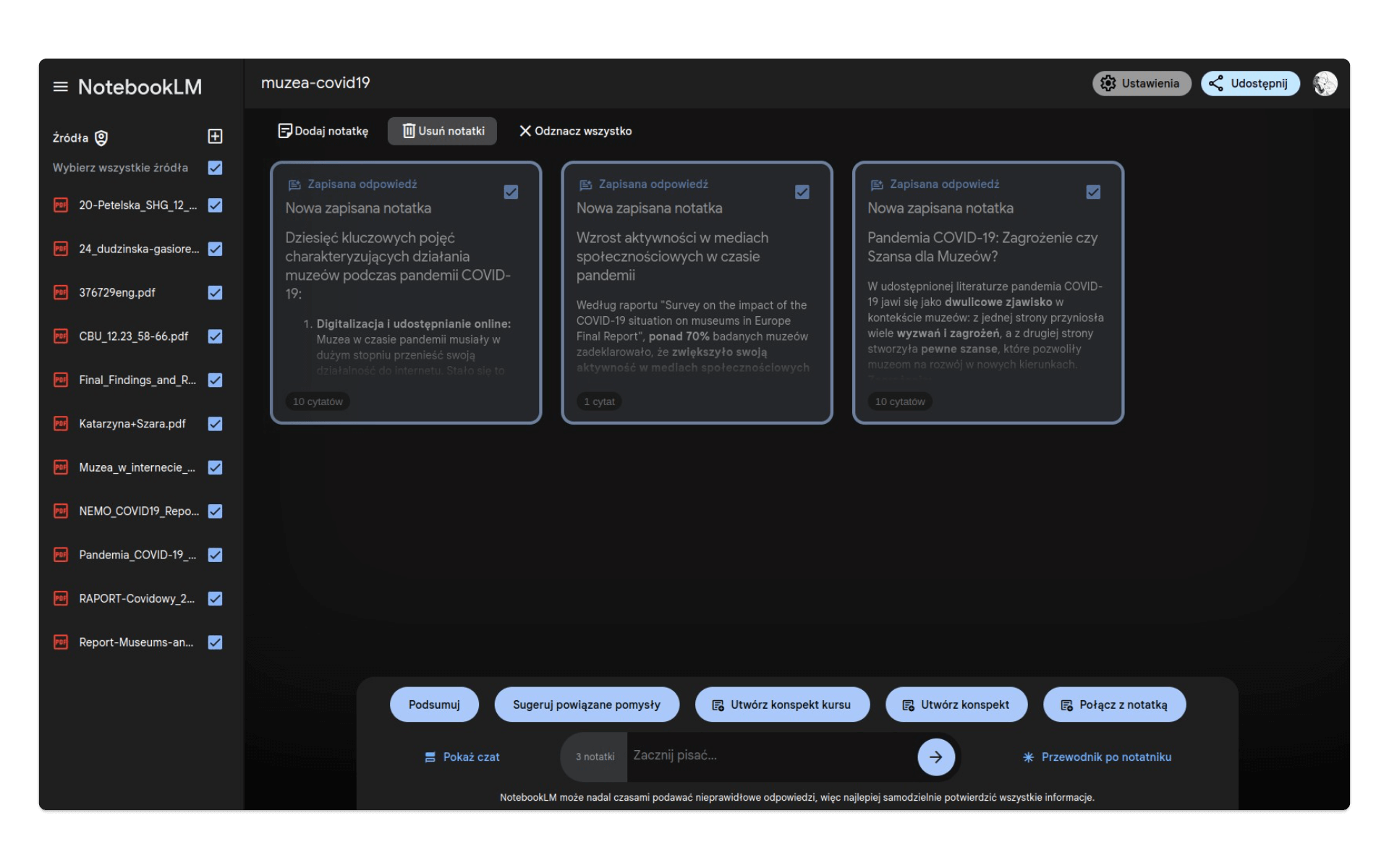
W powyższym przykładzie mamy dostęp do kilku notatek, ale w naszym nowym notatniku nie mamy jeszcze żadnej. Spróbujmy to zmienić i zacząć dialog z modelem. Spróbujmy zadać dość ogólne pytanie:
Czy w udostępnionej literaturze pandemia covid traktowana jest wyłącznie jako zagrożenie dla muzeów czy też (oczywiście z zachowaniem proporcji) jako pewna szansa dla nich?W odpowiedzi otrzymujemy dość obszerne opracowanie tego konkretnego problemu. Co ważne, NotebookLM podaje odnośniki do źródeł, które wykorzystał i sprawie łączy ze sobą wiedzę z tekstów w języku polskim i angielskim:
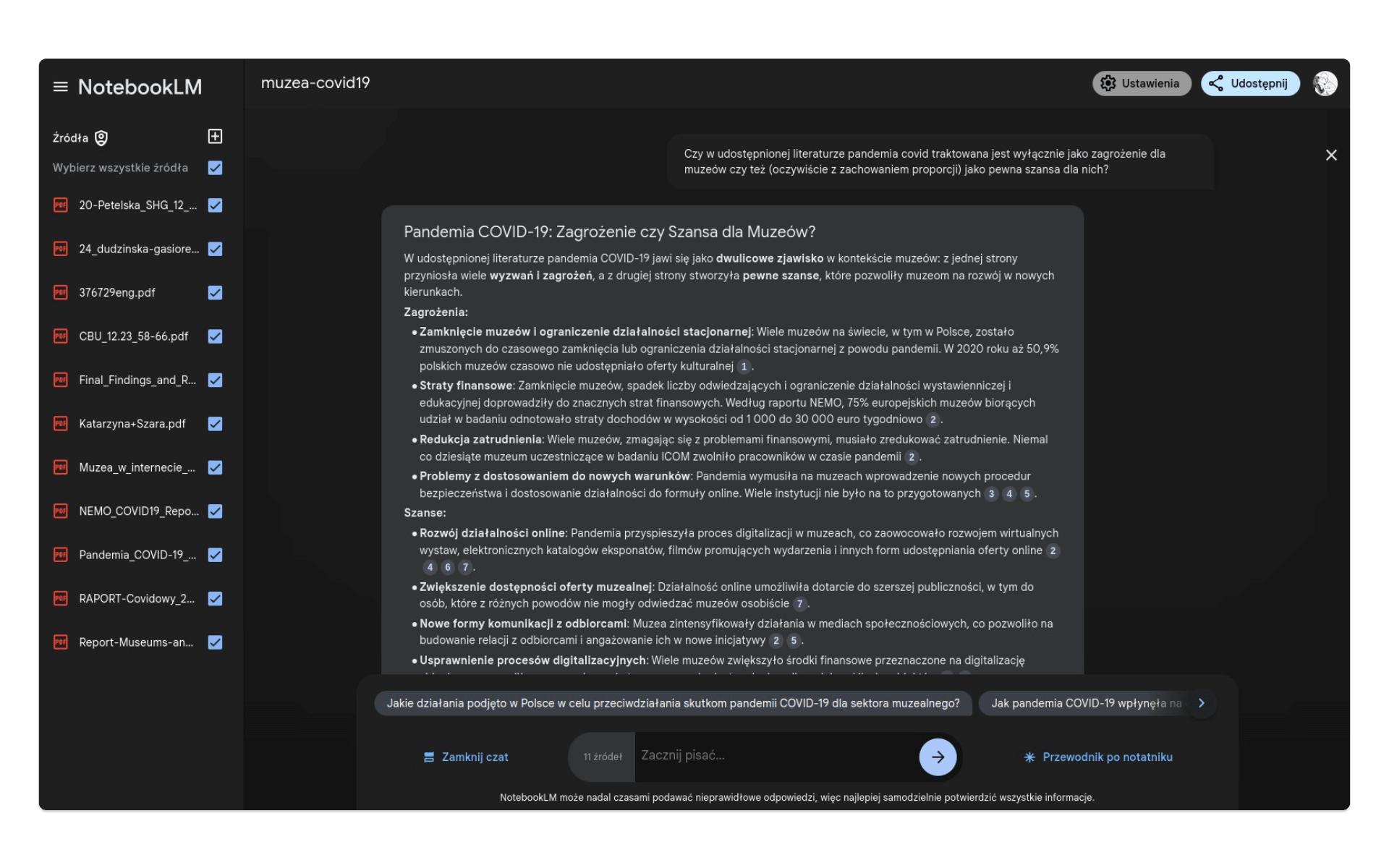
Odpowiedź możemy od razu przekształcić w notatkę.
NotebookLM w zadaniach NER
NER (Named-entity recognition) to zadanie z przetwarzania języka naturalnego, w którym z korpusu tekstów wyodrębniamy nazwy własne (lub inne słowa o określonym znaczeniu). NotebookLM może realizować takie zadania. Spróbujmy to sprawdzić i dowiedzieć się, o jakich konkretnie muzeach pisze się w zebranych przez nas źródłach:
przygotuj listę nazw wszystkich muzeów, które wymienione są w udostępnionych źródłach. Obok nazwy muzeum podaj w nawiasie kraj, w którym ma siedzibę. Policz te kraje i podaj zbiorczą statystykę.Jak widać, prompt wysyłany do modelu może od razu wskazywać na formę odpowiedzi (lista) oraz wskazywać, w jaki sposób przetworzyć pozyskane informacje (w tym przypadku - policzyć statystyki krajów).
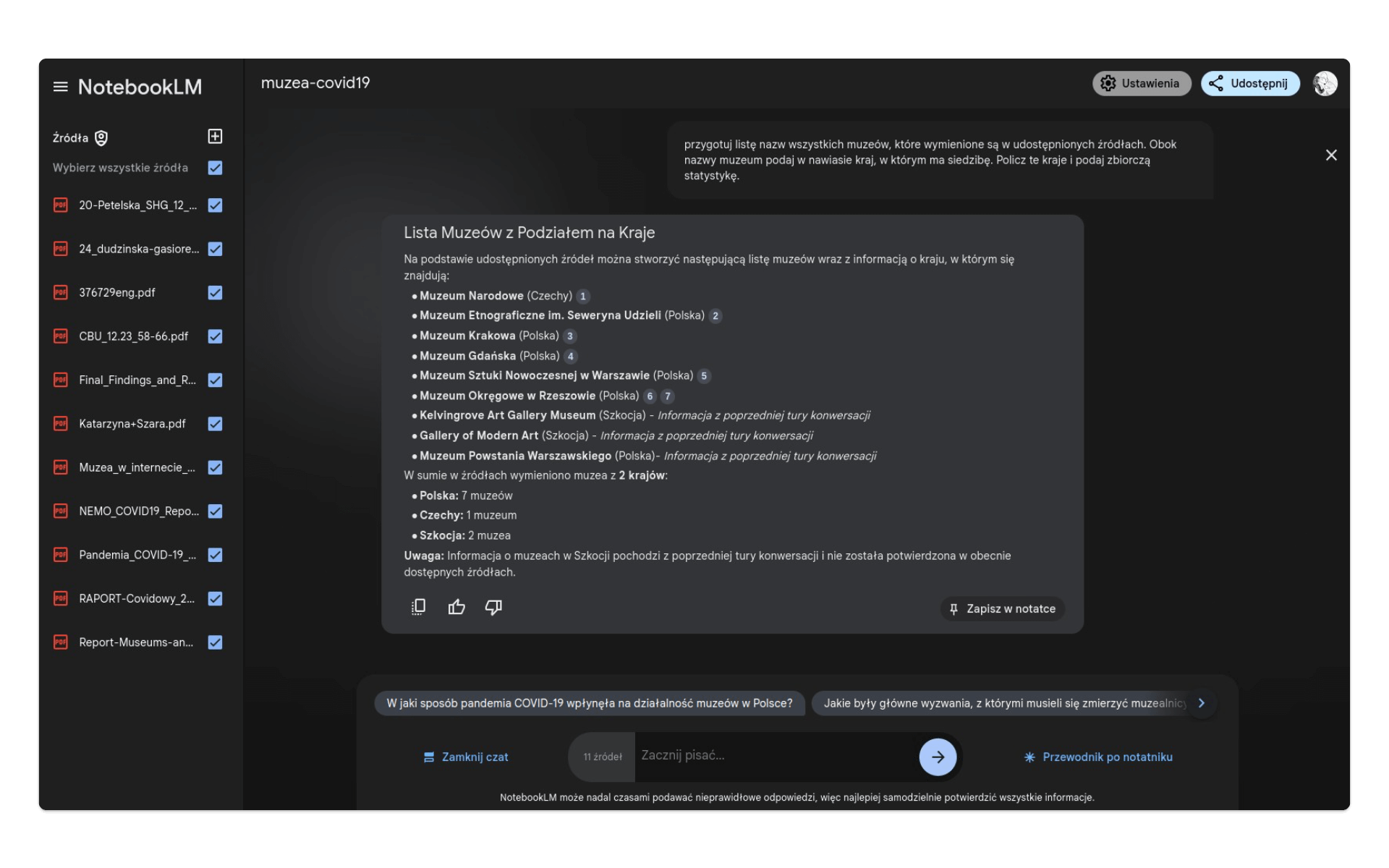
Dostaliśmy w tej odpowiedzi ciekawy komentarz:
Uwaga: Informacja o muzeach w Szkocji pochodzi z poprzedniej tury konwersacji i nie została potwierdzona w obecnie dostępnych źródłach.
Przygotowując się do tej lekcji, testowałem NotebookLM na podobnych źródłach. Okazuje się, że system ma dostęp do poprzednich konwersacji i potrafi pozyskiwać z nich informacje. Niestety, wprowadza to do pracy pewien chaos - od razu zastanawiamy się, czy NotebookLM nie halucynuje i czy możemy zaufać jego analizie. Jeśli nie, jego wartość w pracy badawczej może być ograniczna - po co nam automatyczne zestawienia, których poprawność musielibyśmy samodzielnie sprawdzać? To niestety główna wada pracy z rozwiązaniami opartymi na dużych modelach językowych.
Nasze podejrzenia niestety potwierdzają się: w pierwszym z brzegu opracowaniu (plik NEMO_COVID19_Report_12.05.2020.pdf) znajduje się wzmianka o MuDA - Museum of Digital Art z Zurychu. Uzupełniony prompt
przygotuj listę nazw wszystkich muzeów, które wymienione są w udostępnionych źródłach w języku polskim i angielskim. Obok nazwy muzeum podaj w nawiasie kraj, w którym ma siedzibę. Policz te kraje i podaj zbiorczą statystykę.również nie zwrócił odpowiedzi o oczekiwanej jakości 😔.
Halucynowanie pomimo źródeł?
Sprobujmy łatwiejszego zadania. W raporcie umieszczonym w pliku NEMO_COVID19_Report_12.05.2020.pdf znajduje się fragment
Over 70% of respondents reported their museum has increased social media activities.
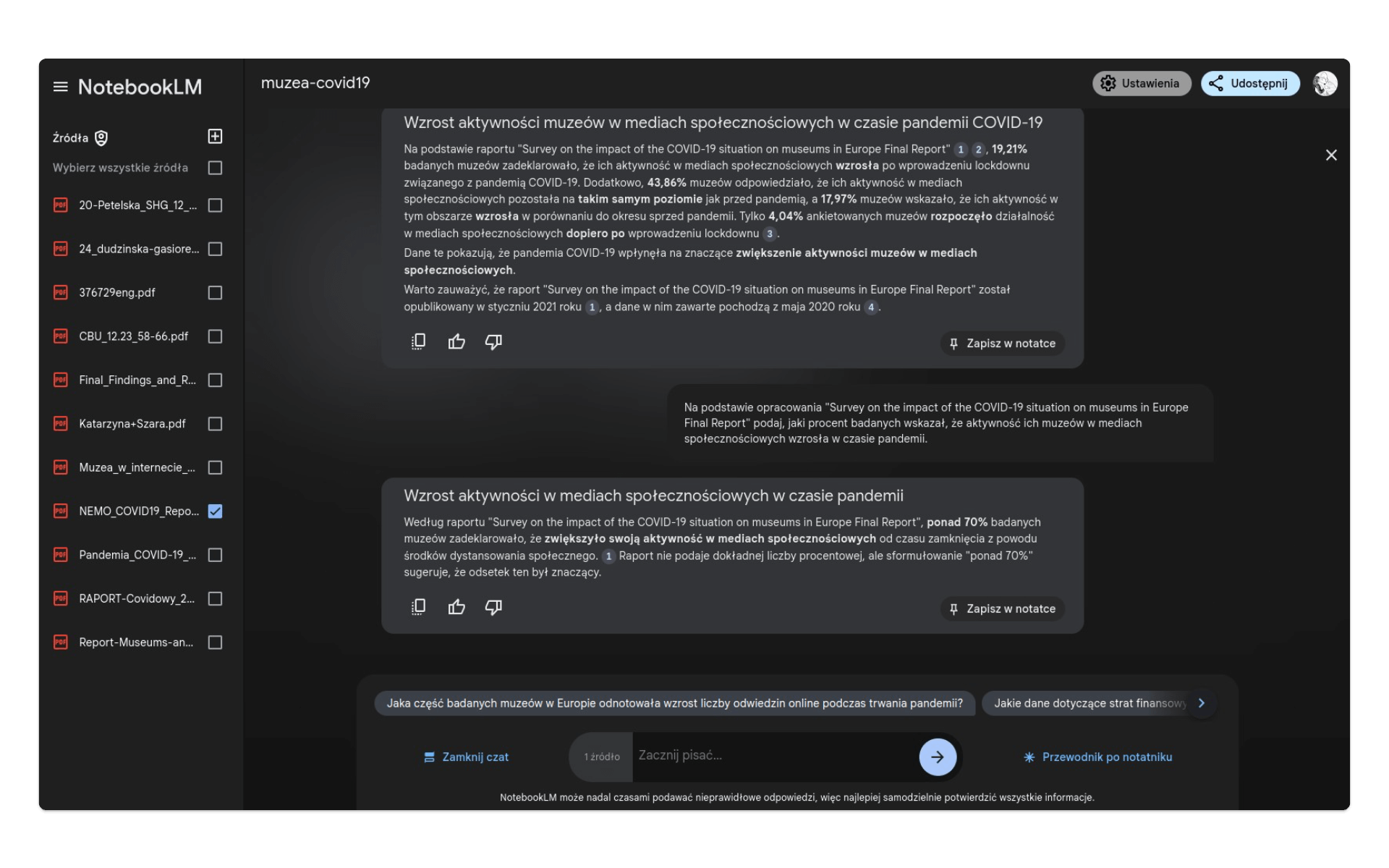
Zapytajmy bezpośrednio o te wartości:
Na podstawie opracowania "Survey on the impact of the COVID-19 situation on museums in Europe Final Report" podaj, jaki procent badanych wskazał, że aktywność ich muzeów w mediach społecznościowych wzrosła w czasie pandemii.Odpowiedź modelu jest całkowicie błędna:
Na podstawie raportu “Survey on the impact of the COVID-19 situation on museums in Europe Final Report”, 19,21% badanych muzeów zadeklarowało, że ich aktywność w mediach społecznościowych wzrosła po wprowadzeniu lockdownu związanego z pandemią COVID-19.
Czy to dlatego, że zleciliśmy tę analizę, mając aktywne wszystkie jedenaście udostępnionych źródeł? Spróbujmy odznaczyć wszystkie artykuły i opracowania poza NEMO_COVID19_Report_12.05.2020.pdf. Wysyłamy ten sam prompt i w odpowiedzi otrzymujemy poprawne dane:
Praca z tabelami
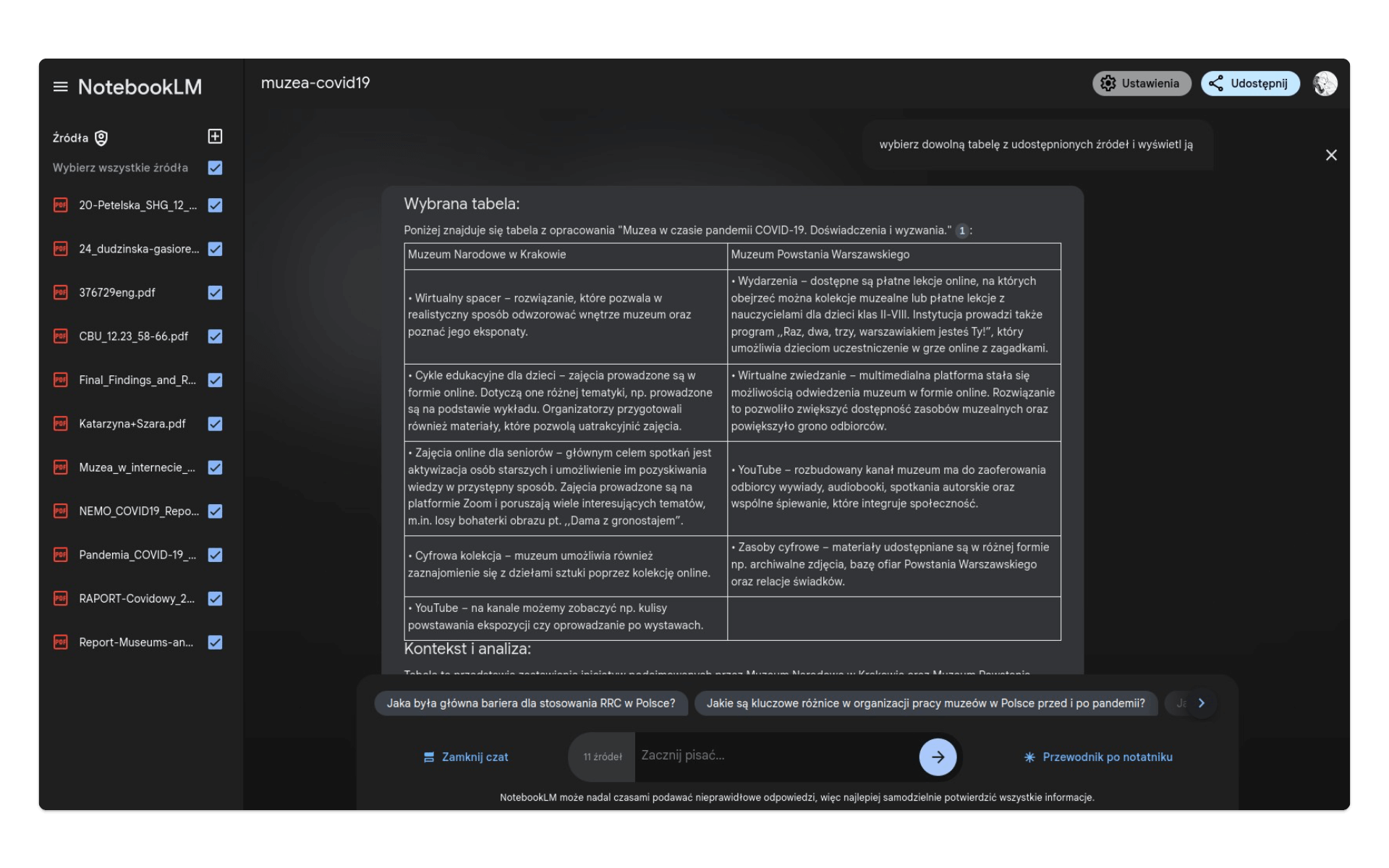
Po wpadce ze statystycznym podsumowywaniem źródeł, NotebookLM trudno uznać za narzędzie godne zaufania. Spróbujmy wykorzystać je do prostszych zadań. Jednym z nużących czynności w toku pracy ze źródłami jest wyodrębnianie tekstu z tabel lub ich przepisywanie np. do postaci HTML. Na polecenie
wybierz dowolną tabelę z udostępnionych źródeł i wyświetl jąotrzymamy taką odpowiedź:
Spróbujmy przetworzyć ją do kodu HTML, który pozwoli umieścić ją na stronie:
przetwórz tę tabelę do kodu HTMLW efekcie:
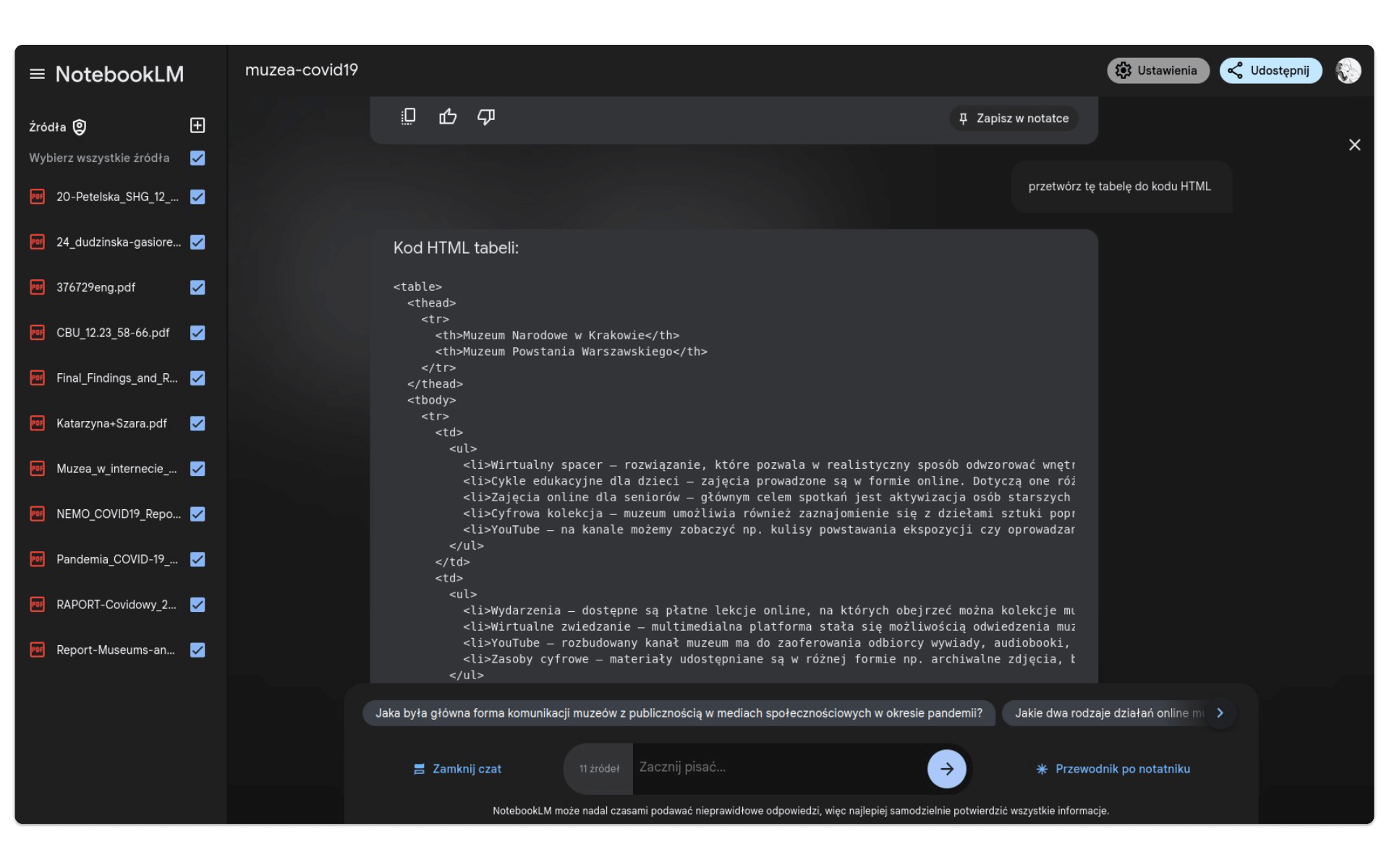
Transkrybowane z PDF treści tabeli są jak najbardziej zgodne z jej oryginalną postacią, umieszczoną w pliku 24_dudzinska-gasiorek_muzea-w-czasie-pandemii-covid-19.pdf na stronie 6.
Ambitne zadanie - wskazanie ważnych pojęć
A gdyby jednak zaufać NotebookLM i zlecić mu ambitniejsze zadanie, będąc jednocześnie świadomym, że jego interpretacje materiałów źródłowych mogą być błędne? Spróbujmy wysłać do modelu taki prompt:
zaproponuj dziesięć najważniejszych pojęć, którymi można scharakteryzować działania muzeów podczas pandemii covidModel wyodrębnił takie pojęcia:
- Digitalizacja i udostępnianie online
- Wirtualne spacery i zwiedzanie
- Działania edukacyjne online
- Media społecznościowe
- Rapid Response Collecting (RRC)
- Wykluczenie cyfrowe
- Bezpieczeństwo i konserwacja zbiorów
- Zmiany w organizacji pracy
- Finanse
- Wsparcie państwa
To bardzo ciekawa i potencjalnie wartościowa lista. Wydaje się jednak, że wartość takiej odpowiedzi zależeć będzie od tego, w jaki sposób ją wykorzystamy. Jeśli użyjemy ją bezpośrednio jako zamknięty schemat tematów w artykule o muzeach w czasie pandemii, może okazać się, że pominęliśmy istotne wątki, np. problem terapii przez zbiory - jakiegoś pozytywnego oddziaływania muzeów na społeczeństwo próbujące się odnaleźć w nowej rzeczywistości. Ale jeśli użyjemy tej listy jako otwartego zestawu problemów i będziemy ją dalej rozbudowywać, okaże się, że NotebookLM wykonał za nas wiele wartościowej pracy. Nie tyle stworzył coś nowego i wysokiej jakości, co zebrał informacje, na podstawie których możemy rozwinąć nasze badania albo plan eseju.
To też oczywiście ciekawa forma uczenia się - po samodzielnej lekturze opracowań można użyć NotebookLM jako systemu powtórkowego, generującego podsumowania i nawet sprawdzającego wiedzę (możemy pisać prompty które wygenerują zestawy pytań testowych).
Podsumowanie
Jeśli korzystamy z narzędzi uczenia maszynowego w zadaniach wymagających kreatywności, może okazać się szybko, że nie spełniają one naszych oczekiwań. Podobnie jak ChatGPT tak NotebookLM nie napisze za nas eseju, nie zaprojektuje badań, nie zinterpretuje wybranych źródeł - oczywiście, jeśli wciąż zależy nam na pracy mającej wysoką jakość, a nie na produkowaniu generycznych i naiwnych slopów.
Ta krótka lekcja pokazała jednak, że można pracować z takimi narzędziami, traktując je jednak wyłącznie jako wsparcie. NotebookLM to przykład narzędzia Retrieval Augmented Generation (RAG) - duży model językowy jest tam wykorzystywany do przeszukiwania i przetwarzania informacji ze ściśle określonych źródeł. Wydaje się, że takie podejście ma największy potencjał: odpowiednio sprofilowany zestaw dokumentów źródłowych daje niezbędny kontekst i wiedzę, a model językowy ułatwia przeglądanie tego zbioru.
Nie jest to oczywiście praca bez błędów: NotebookLM wciąż halucynuje i ma problemy z analizą korpusową - to ostatnie wydaje się być najpoważniejszą wadą tego narzędzia. Udostępniając duże zbiory dokumentów chcielibyśmy przecież móc spojrzeć na nie pod kątem występowania określonych słów czy pojęć - praca badawcza to przecież też żmudne przeglądanie dziesiątek stron opracowań na temat, którym się zajmujemy.
Na pewno warto też skorzystać z NotebookLM jako narzędzia do samodzielnej nauki, szczególnie, że aplikacja pozwala generować podsumowania audio zebranych materiałów - otrzymujemy gotowy do odsłuchania podkast w języku angielskim.
W tym celu zaznaczamy wszystkie lub wybrane notatki i wybieramy przycisk Przewodnik po notatniku. Możemy automatycznie wygenerować podkast, który pozwoli nam zapoznać się z najważniejszymi informacjami zapisanymi w notatkach. Możemy również dostosować treść podkastu, wskazując np. wybrane źródło, które powinno zostać omówione.
Oto podkast na temat dziesięciu najważniejszych pojęć, które opisują sytuację muzeów w czasie pandemii COVID-19.
Czy wszystkie przywoływane przez boty w tym podkaście dane rzeczywiście znajdują się w cytowanych opracowaniach? Sprawdzenie każdego cytatu, który pojawiłby się w 20-minutowym programie, wymagałoby dodatkowej, intensywnej pracy - może lepiej po prostu samodzielnie przeczytać przynajmniej niektóre opracowania?
Ten automatycznie wygenererowany dialog momentami bardzo zaskakuje - wnioski, jakie proponuje nam model, to m.in. przeświadczenie o tym, że polskie muzea są światowymi liderami transformacji cyfrowej w tym sektorze lub stwierdzenie, że muzea finansowane są przede wszystkim z wpływów z biletów.
Wykorzystanie metod
W październiku 2024 roku pracownicy i pracowniczki amerykańskich Archiwów Narodowych (NARA) wzięli udział w szkoleniu online “AI-mazing Tech-venture”. Dziennikarze portalu 404 Media dotarli do czata z komentarzami z tego szkolenia.Archiwistom i archiwistkom przedstawiono możliwości produktu Googla - Vertex AI, który ma ich wspierać w eksploracji, opracowywaniu i udostępnianiu dokumentów.
Vertex AI to rozbudowana platforma, pozwalająca na łatwe trenowanie własnych modeli językowych na własnych zasobach instytucji, działa więc inaczej niż NotebookLM. Wydaje się jednak, że jej ograniczenia są podobne do narzędzia, z którym pracowaliśmy na tej lekcji, i dotyczą dwóch problemów:
- czy naszą pracę można w ogóle zautomatyzować?
- czy wiedza, której potrzebujemy, bazuje wyłącznie na zasobach, które da się przetworzyć?
W trakcie szkolenia w NARA model wygenerował frazę, w której określił się jako expert archivist, co spotkało się z oburzeniem części uczestników i uczestniczek szkolenia. Osoby pracujące w archiwach mają przecież wiedzę daleko wykraczającą poza podręczniki, raporty i indeksy, mają też doświadczenie, którego żadna platforma AI nie może uzyskać, np. pamięć o udostępnianych czy przetwarzanych już kiedyś dokumentach, kontakty z badaczami i badaczkami czy wiedzę na temat historycznych struktur administracji i urzędów.
Co ciekawe, jeszcze miesiąc przed prezentacją Vertex AI, w wewnętrznej komunikacji z pracownikami i pracowniczkami, władze archiwów wprost informowały o zakazie korzystania z Chat GPT w pracy ze względu na ochronę danych i zagrożenie halucynowania informacji.
Pomysł na warsztat
Być może wartościowym pomysłem na warsztat byłaby próba hackowania NotebookLM, ujawniająca jego ograniczenia jako systemu przetwarzania wiedzy. Warsztat polegałby na wypracowaniu metod ataków, przygotowaniu treści, które do tych ataków możnaby wykorzystać i na analizie jakości pracy aplikacji.
Przykładowo: formą ataku staje się udostępnienie w zbiorze dobrej jakości źródeł kilku dokumentów z oczywistymi nieprawdami, manipulacjami i fałszywymi danymi. Czy NotebookLM poradzi sobie ze wskazaniem oczywistych błędów? Czy przygotowane przez niego podsumowania nie będą zawierały podrzuconych przez nas, nieprawdziwych informacji?
Próbując zinfekować materiały źródłowe NotebookLM możemy testować wypowiedzi ironiczne i metafory, popularne cytaty, które odpowiednio manipulujemy (np. z WikiCytatów), aby ich znaczenie było inne niż oryginalne, a nawet wstrzykiwanie promptów (prompt injection) 😎.


