
Wprowadzenie
Jedną z ważniejszych koncepcji cyfrowej humanistyki jest czytanie zdystansowane (distant reading) - pojęcie to wprowadził Franco Moretti. To alternatywa wobec uważnej lektury (close reading), niemożliwej przy dużej liczbie tekstów. W czytaniu zdystansowanym tekst staje się źródłem danych i te dane - a nie tekst - podlegają interpretacji. Kiedy tekst przetwarzamy na dane, używamy wizualizacji, żeby ułatwić interpretację. Jedną z popularnych wizualizacji tekstów jest chmura słów (kluczowych), budowana na podstawie statystyki występowania w tekście określonych słów lub fraz.
Cele lekcji
Celem lekcji jest przygotowanie wizualizacji, informującej o obiektach, które najczęściej pojawiają się na obrazach w kolekcji Muzeum Narodowego w Warszawie. Źródłem danych do wizualizacji będą Wikidane, a narzędziem ich opracowania - platforma Lexos, udostępniana przez amerykański Wheaton College.
Efekty
Efektem naszej pracy będzie przetworzony korpus nazw obiektów i wizualizacje w postaci chmury słów i wizualizacji bańkowej (bubbleviz). Dzięki lekcji nauczymy się też zwracać uwagę na ograniczenia wizualizacji danych / tekstów - każda wizualizacja jest interpretacją, a dane nigdy nie są neutralne.
Wymagania
Chmury słów można z łatwością opracowywać i generować w R i Pythonie, ale w tej lekcji skorzystamy z otwartych i darmowych narzędzi przeglądarkowych. W pierwszym etapie lekcji konieczny jest dostęp do ChatGPT lub podobnego narzędzia - np. wyszukiwarki Ecosia. Dzięki nim łatwo przygotujemy kwerendę SPARQL do Wikidanych.
Przed przystąpieniem do pracy warto przeczytać wcześniejszą lekcję na temat korzystania z Wikidanych.
Część merytoryczna
Chmura słów to jeden ze sposób prezentacji określonych cech tekstu (czy tekstów). W tej formie wizualizacji wielkość słowa, które prezentowane jest w chmurze w otoczeniu innych słów, zależy od jego liczebności w tekście źródłowym. Używając chmury słów przyjmujemy, że najczęściej czy najrzadziej występujące słowa lub frazy mogą coś powiedzieć o tekście. Liczba wystąpień określonego słowa może mieć znaczenie w interpretacji całej treści.
Chmura słów kluczowych może być przydatna w szybki zorientowaniu się w treści tekstu, zidentyfikowania najczęściej pojawiających się w nim pojęć, zrozumienia jego kontekstu. Może też pomóc w odkrywaniu związków między różnymi słowami (pojęciami, osobami) lub wskazywać na tematy dominujące w tekście.
Ograniczenia chmury słów
Dobrym przykładem ograniczeń chmury słów jako reprezentacji tekstu byłby na przykład korpus recenzji kolejnych filmów z serii Gwiezdne Wojny. To, że w chmurze słów dominowałyby frazy takie jak Gwiezdne Wojny, moc czy jedi, raczej nie powiedziałoby nam nic o treści recenzji. Czy rzeczywiście takie słowa w badanych recenzjach są kluczowe? Być może lepiej byłoby skupić się na najmniej licznych słowach i zastanowić się, dlaczego używane są tak rzadko?
Chmura słów może być nieefektywną wizualizacją także dlatego, że same słowa mają różne znaczenia i konteksty. Niektóre nawet nie niosą żadnych znaczeń, jeśli interpretujemy je osobno - to tak zwane stopwords (i, w, na, się) - źle przygotowane chmury słów poznacie po tym, że znajdują się w nich takie elementy. Poniżej przykład błędnie przygotowanej chmury słów kluczowych, wygenerowanej na podstawie tekstu recenzji z “Dwutygodnika”.

Problemem są też niejednoznaczności. W analizie tekstów religijnych czy - tak jak w naszym przypadku - w analizie obiektów widocznych na obrazach z kolekcji muzealnej z pewnością pojawi się słowo Jezus i frazy Jezus Chrystus. Możemy zakładać, że te dwa słowa niosą identyczne znaczenie, ale sytuacja robi się bardziej skomplikowana, kiedy w liście słów pojawia się dzieciątko Jezus 🙂. Jezus i dzieciątko Jezus, jaguar i samochód, autor i autorka, droga (jako cecha) i droga jako część infrastruktury transportowej - to tylko niektóre przykłady, jakie mogą rozbić nam interpretację chmury słów. Powinniśmy mieć świadomość, że każda wizualizacja jest interpretacją - dlatego warto też publikując chmurę słów informować, w jaki sposób została przygotowana.
Nie ma też jednej metody. Przygotowując chmurę słów, a więc zliczając ich występowanie w tekście czy tekstach, powinniśmy pracować na podstawowych wersjach słów. Lematyzacja to proces przekształcania słowa do jego podstawowej, słownikowej formy, czyli lematu. Słowa poszedłem, autorka, Róża po lematyzacji przyjmą postać iść, autor, róża - jak widać nawet forma podstawowa nie chroni nas przed błędnymi interpretacjami, w których albo tracimy możliwość analizy genderowej (wszystkie autorki wymienione w badanych tekstach to teraz autorzy) albo mieszamy nazwę kwiatu z imieniem.
To, jak przygotujemy słowa do zliczenia, jest podstawowym wyzwaniem w budowaniu chmury słów i może bardzo mocno wpływać na to, jak interpretowane będą teksty, które ilustrujemy naszą wizualizacją.
Zbiory MNW w Wikidanych
Na stronie dostępna jest już lekcja poświęcona Wikidanym - warto się z nią zapoznać. Przypomnę tylko, że Wikidane to semantyczna baza danych, pozwalająca na budowanie bardzo szczegółowych kwerend, eksplorujących cechy i relacje między obiektami opisanymi w tej bazie.
Teraz skorzystamy z Wikidanych, aby pobrać informacje na temat obiektów, których wizerunki pojawiają się na obrazach pozostających w zbiorach Muzeum Narodowego w Warszawie. Można spodziewać się przy tym, że informacje te mogą nie być pełne i dokładne. Co prawda w metadanych zbiorów dostępnych na stronie muzeum cyfrowego MNW znajdują się tagi opisujące to, co jest widoczne na konkretnym obiekcie - żeby zebrać te informacje, musielibyśmy się trochę napracować i skorzystać z protokołu OAI-PMH. Niestety w nowej wersji serwisu nie ma dostępu do tego protokołu. Decydujemy się na skorzystanie z Wikidanych, bo to szybsze i łatwiejsze - tematem naszej lekcji są zresztą chmury słów kluczowych, a nie praca z metadanymi muzeów. Przyjmijmy zatem, że informacje przez nas pozyskane nie będą w pełni odzwierciedlać kolekcji MNW.
Aby przygotować zapytanie w języku SPARQL, użyjmy ChatGPT. Zanim to zrobimy, warto sprawdzić identyfikatory cech i obiektów, z którymi będziemy pracować. Jak można zobaczyć w lekcji poświęconej Wikidanym, ChatGPT halucynuje identyfikatory, przez co otrzymujemy błędne dane albo dostajemy puste odpowiedzi. Dlatego w prompcie dodajmy prawidłowe identyfikatory. Pamiętajmy, że w Wikidanych obiekty pozostają między sobą w relacjach, które przypominają zdanie: podmiot + orzeczenie + dopełnienie.
Nasza kwerenda będzie wykorzystywać następujące identyfikatory:
- Q3305213 - obraz (obiekt) jako podmiot
- P195 - bycie w kolekcji (właściwość) – jako orzeczenie
- Q153306 - Muzeum Narodowe w Warszawie (obiekt) - jako część dopełnienia
- P180 - miejsce, osoba lub inny element przedstawiony w treści podmiotu (właściwość) - część dopełnienia.
W systemie Wikidanych wszystkie identyfikatory zaczynające się od Q oznaczają obiekty (np. Muzeum Narodowe w Warszawie) lub grupy/klasy obiektów (np. obrazy). Identyfikatory zaczynające się od P oznaczają właściwości (bycie w kolekcji, obiekt przedstawiony).
No dobrze, zbudujmy nasza kwerendę. Prompt wysłany do ChatGPT ma postać:
napisz kwerendę do wikidanych, która wylistuje obrazy (Q3305213) z kolekcji (P195) muzeum narodowego w Warszawie (Q153306) oraz to co przedstawiają (P180)W rezultacie otrzymamy kod kwerendy w języku SPARQL:
SELECT ?painting ?paintingLabel ?depicts ?depictsLabel
WHERE {
?painting wdt:P31 wd:Q3305213; # obraz
wdt:P195 wd:Q153306; # w kolekcji Muzeum Narodowego w Warszawie
wdt:P180 ?depicts. # przedstawia
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}Wystarczy wysłać ją do konsoli Wikidanych dostępnej pod adresem query.wikidata.org. W efekcie otrzymamy ponad 8 tys. wyników. Pozostaje nam tylko je pobrać (wybieramy opcję z menu po prawej stronie listy wyników - Pobierz - Plik CSV). Poniżej kwerenda i efekt wyszukiwania:
Przygotowanie danych do chmury słów
Informacje o tym, co jest widoczne na obrazach z kolekcji MNW, dostępne są w kolumnie depictsLabel. Oto fragment tych danych:
mężczyzna
sen
maska
młodzież
Knot
kradzież
Solon
Krezus
mężczyzna
starość
Maria z Nazaretu
Powój
Dzieciątko Jezus
altana
granat
papuga
Jezus ChrystusCzy taka lista słów może być wykorzystana do wygenerowania chmury słów kluczowych? Pozornie nie musimy jej dodatkowo opracowywać - wszystkie słowa są w formach podstawowych, brakuje czasowników. Jednak zwróćmy uwagę na frazę Maria z Nazaretu. Nazaret występuje tam w przypadku, a nie w postaci podstawowej. Czy powinniśmy przekształcić tę frazę na dwa osobne, niezależne słowa (Maria, Nazaret), usuwając przy tym z jako stopword? Nie wydaje się to racjonalne.
Nasza chmura słów ma ilustrować to, co widoczne na obrazach w kolekcji MNW. Obraz opisany frazą Maria z Nazaretu przedstawia osobę a nie miejscowość. Podobnie, chociaż Dzieciątko Jezus i Jezus Chrystus to w kontekście historycznym ta sama osoba, w przypadku przedstawień w sztuce sugeruje bardzo różne konteksty - na pewno w obrazach, na których pojawia się Dzieciątko Jezus możemy szukać scen bożonarodzeniowych, pokłonu mędrców itp., a nie choćby scen chrztu w Jordanie. Nie możemy rozbijać tych opisów na poszczególne słowa, nawet gdybyśmy mieli potem sprowadzić je do form podstawowych. Niestety, wiele podstawowych narzędzi do generowania map słów rozbije nam takie frazy i zepsuje wizualizację.
Lexos - opracowanie danych
Platforma Lexos, udostępniana jest przez Wheaton College - możemy też ściągnąć ją na własny dysk. Skorzystamy z niej do wygenerowania chmury słów.
Najpierw wyeksportujmy kolumnę depictsLabel z naszego pliku csv. Możemy zrobić to w Excelu lub Google Sheets. To proste.
Plik zawierający wyłącznie frazy (bez nagłówka - nazwy kolumny) musimy teraz wysłać do aplikacji Lexos. W tym celu korzystamy z przycisku Browse.
Jeśli w polu Upload List pojawi się nazwa pliku, który wysłaliśmy - wszystko jest w porządku. Jesteśmy na dobrej drodze do przygotowania wizualizacji. Z menu Visualize wybieramy opcję Word Cloud, która wygeneruje nam chmurę słów zawierającą 100 najpopularniejszych terminów.
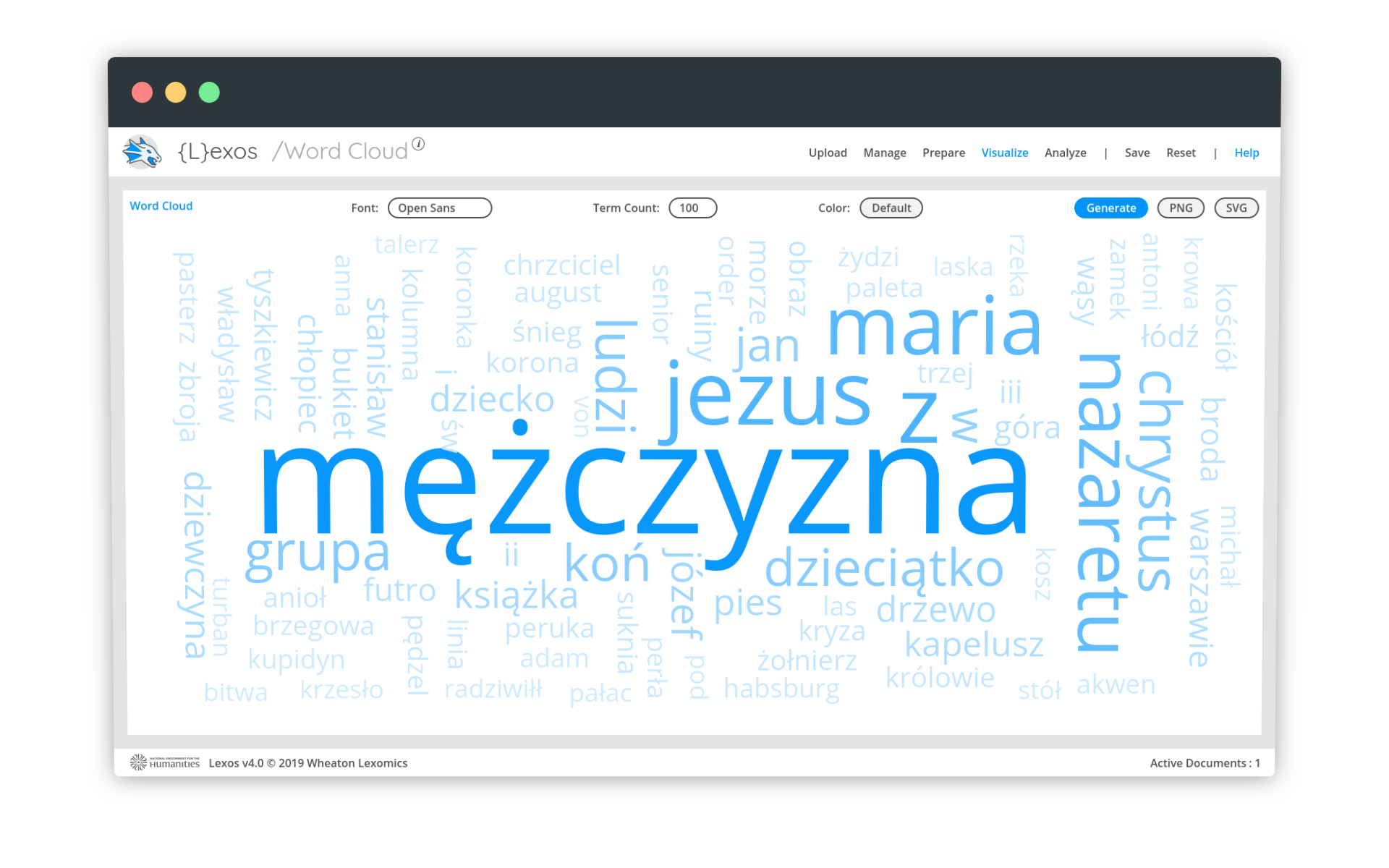
Niestety, system rozbił nam frazy i stąd wyróżnione stopwordsy takie jak z, w czy III. Podobny błąd pojawi się na wizualizacji bańkowej, dostępnej w menu pod nazwą BubbleViz. Czy można coś na to poradzić? Tak 😎
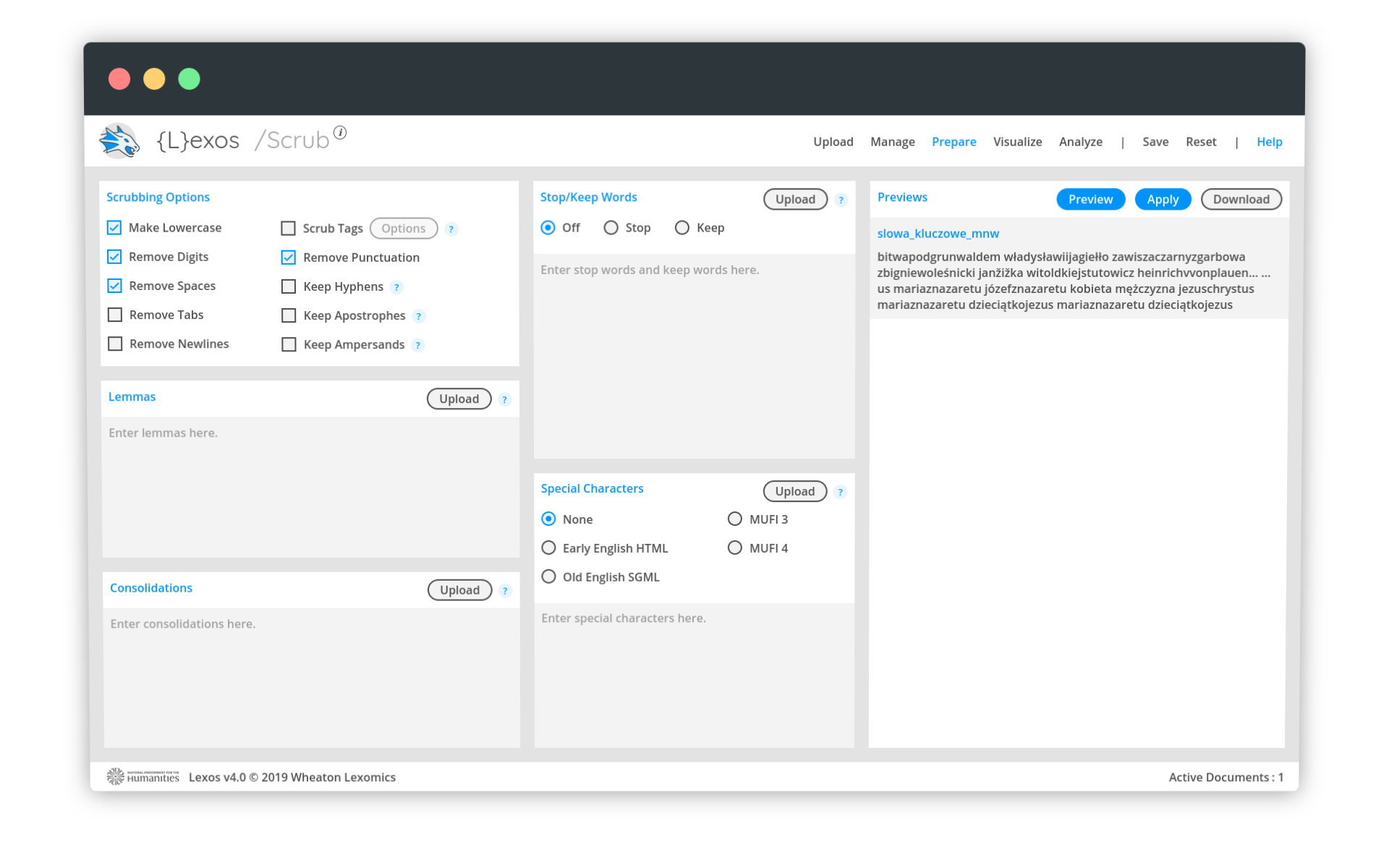
Dobrym sposobem na zablokowanie rozbijania fraz jest… zrobienie z każdej z nich jednego słowa. Nie interesuje nas przecież to, czy Lexos rozumie czy nie rozumie znaczenia wysłanych do niego tekstów. Ma po prostu policzyć wystąpienia kolejnych ciągów tekstowych i zbudować wizualizację.
W menu Prepare wybieramy opcję Scrub (wyczyść albo uporządkuj). Po lewej stronie ekranu znajduje się panel Scrubbing Options. Zaznaczamy tam opcję Remove spaces. Po usunięciu spacji nasze dane będą wyglądać tak:
mężczyzna
sen
maska
młodzież
Knot
kradzież
Solon
Krezus
mężczyzna
starość
MariazNazaretu
Powój
DzieciątkoJezus
altana
granat
papuga
JezusChrystusAktualna wersja tekstu, który będzie wizualizowany, wyświetlana jest po prawej stronie ekranu. Kliknięcie Preview pozwoli podejrzeć nam zmiany, a Apply - zastosować je do przygotowania wizualizacji.
Gotowe wizualizacje i niespodziewane błędy
Klikamy w menu Visualize - Word Cloud. Chmura słów została wygenerowana:
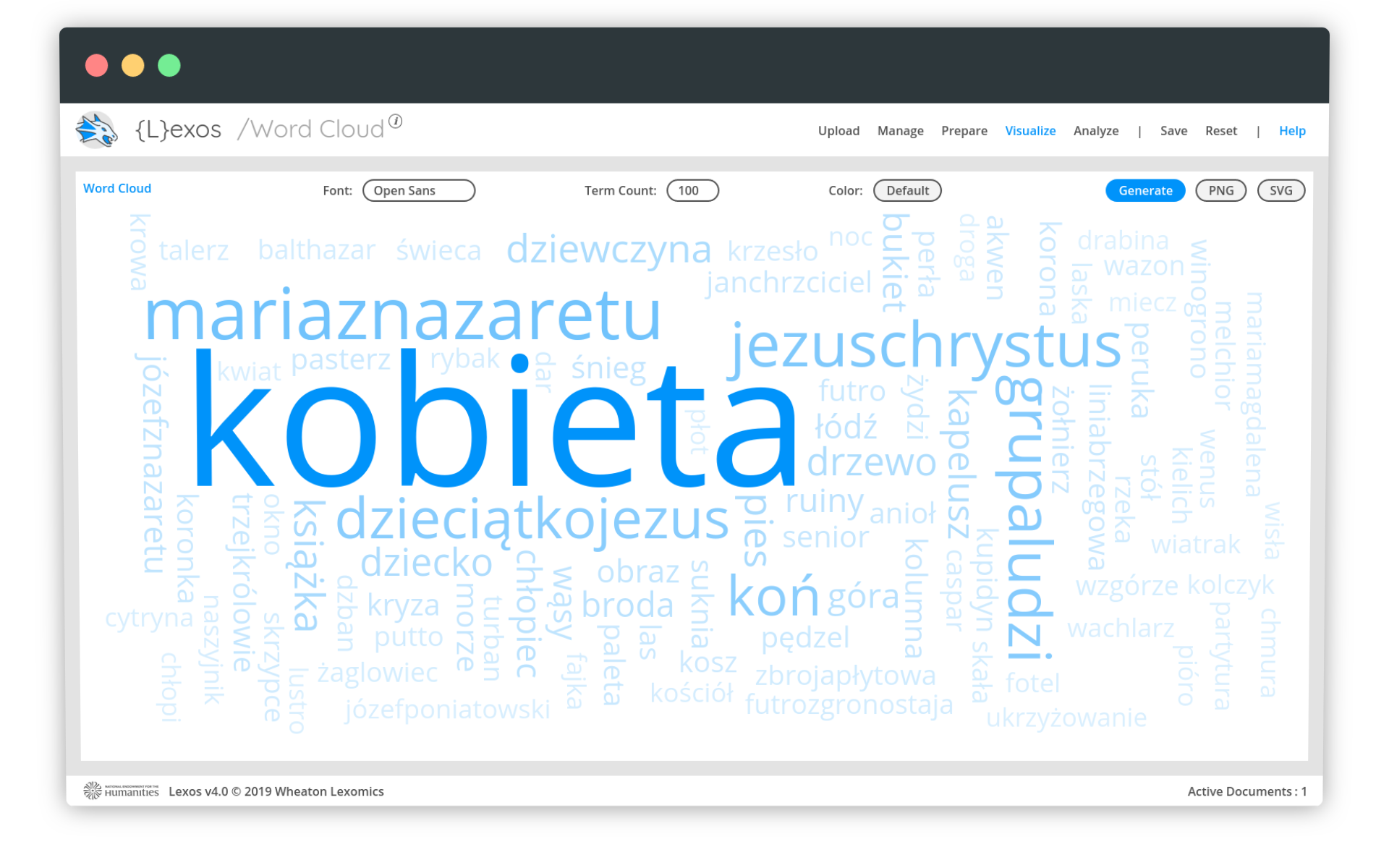
Wydaje się, że wszystko jest w porządku i możemy interpetować dane. Niestety, wystarczy odświeżyć wizualizację (np. przez przeładowanie strony), żeby chmura słów się zmieniła. Nie chodzi przy tym o zmianę kolorów czy układu słów, ale zmianę na poziomie informacji:
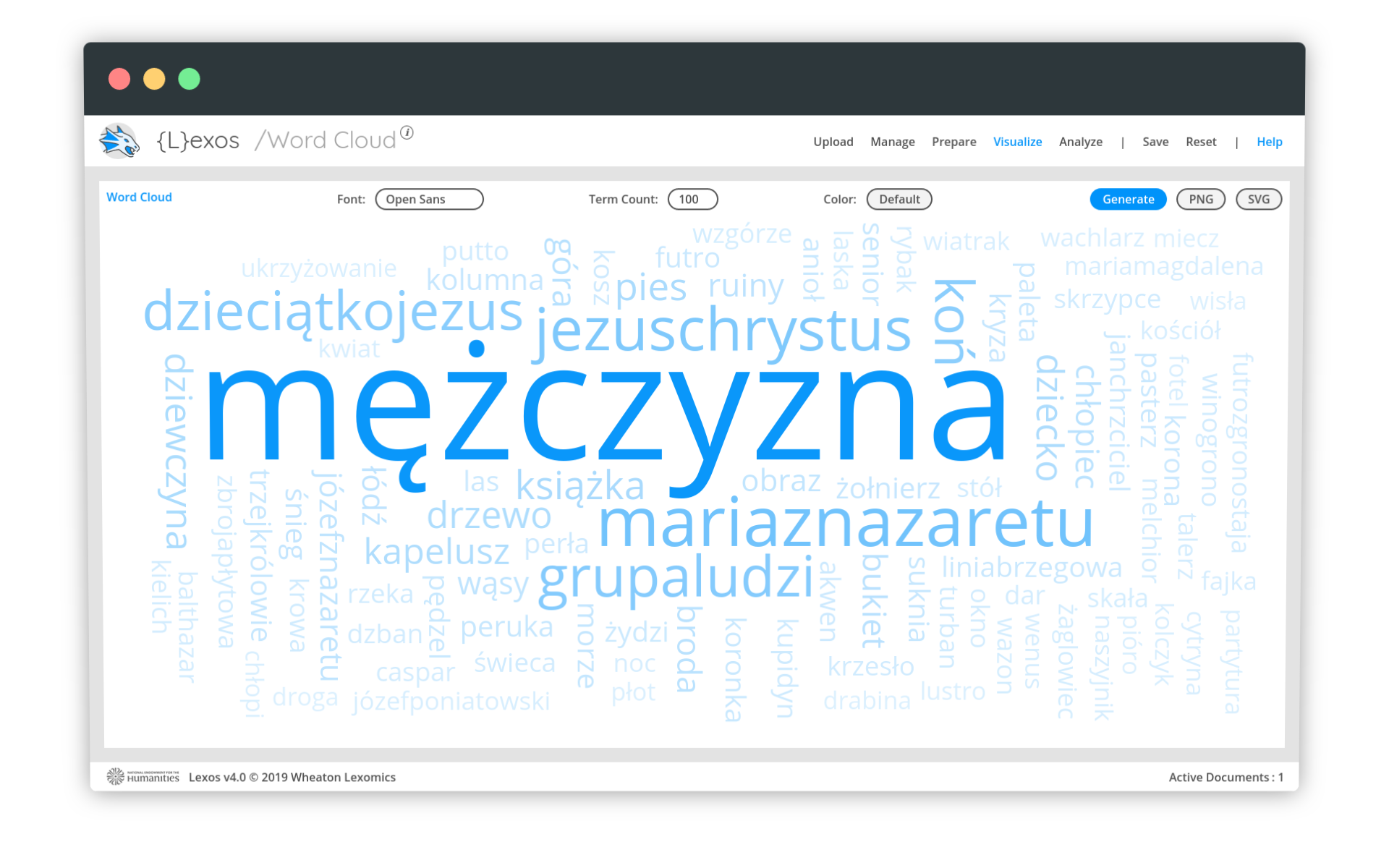
Wiadomo z danych, że słowo kobieta i mężczyzna to najpopularniejsze słowa w naszym zestawie. Niestety, Lexos, generując wizualizację, czasem z jakiegoś powodu je pomija. Szybka analiza kodu źródłowego tej aplikacji (tutaj i tutaj) nie pozwala na łatwe ustalenie, dlaczego tak się dzieje.
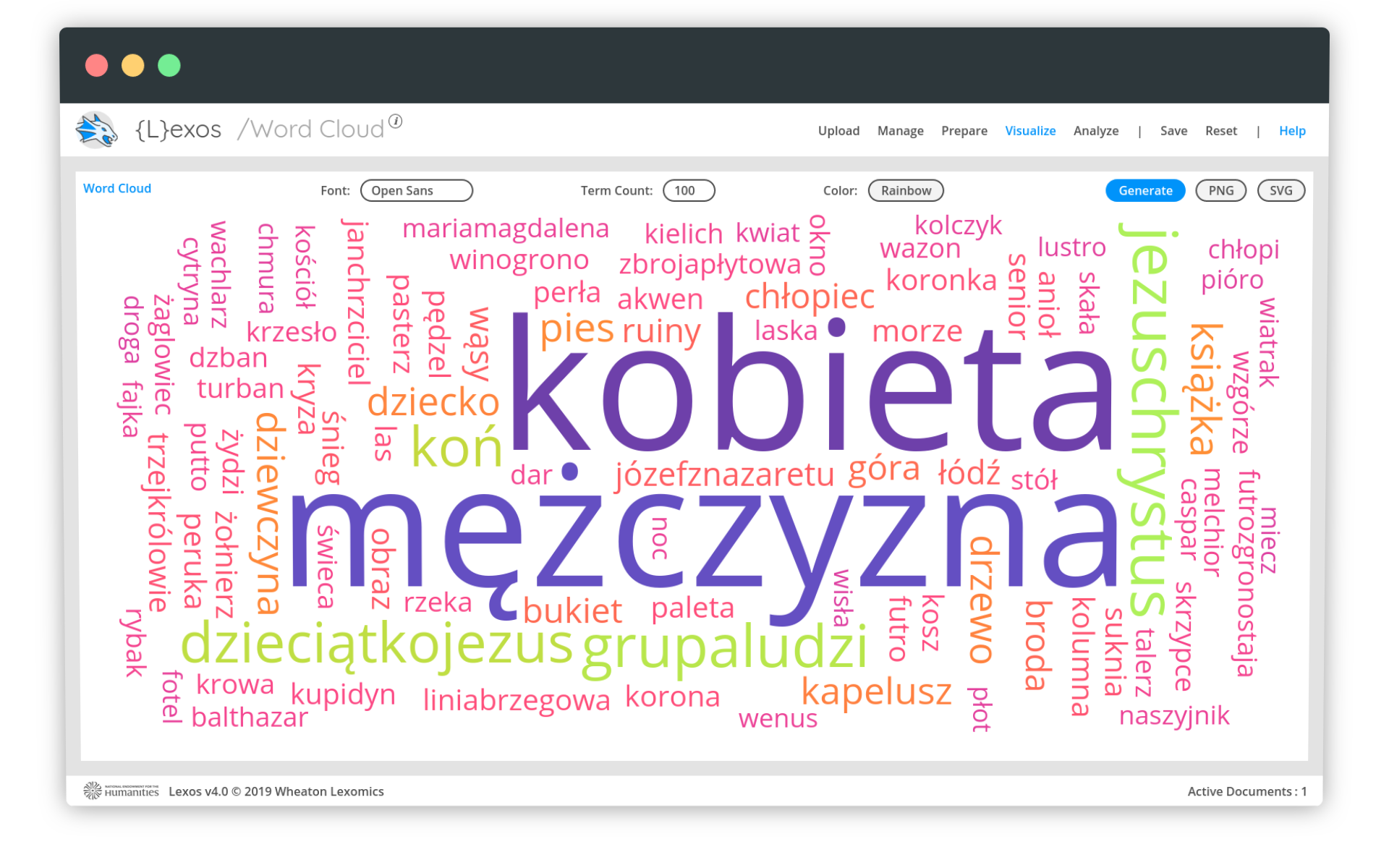
Ostatecznie okazuje się, że błąd wynika z mechanizmu generowania layoutu chmury, zastosowanego w bibliotece d3-cloud, wykorzystywanej w programie Lexos. Jeśli najczęstsze słowa nie pasują do layoutu chmury (są za duże, aby się w niej zmieścić), algorytm d3-cloud je pomija. Aby ominąć ten błąd, należy po prostu jeszcze raz wygenerować chmurę, mając w pamięci, jakie słowa powinny w niej dominować (można to sprawdzić w widoku Prepare - Tokenize).
Po kilku próbach i odświeżaniu wizualizacji, udaje się uzyskać zakładany efekt:
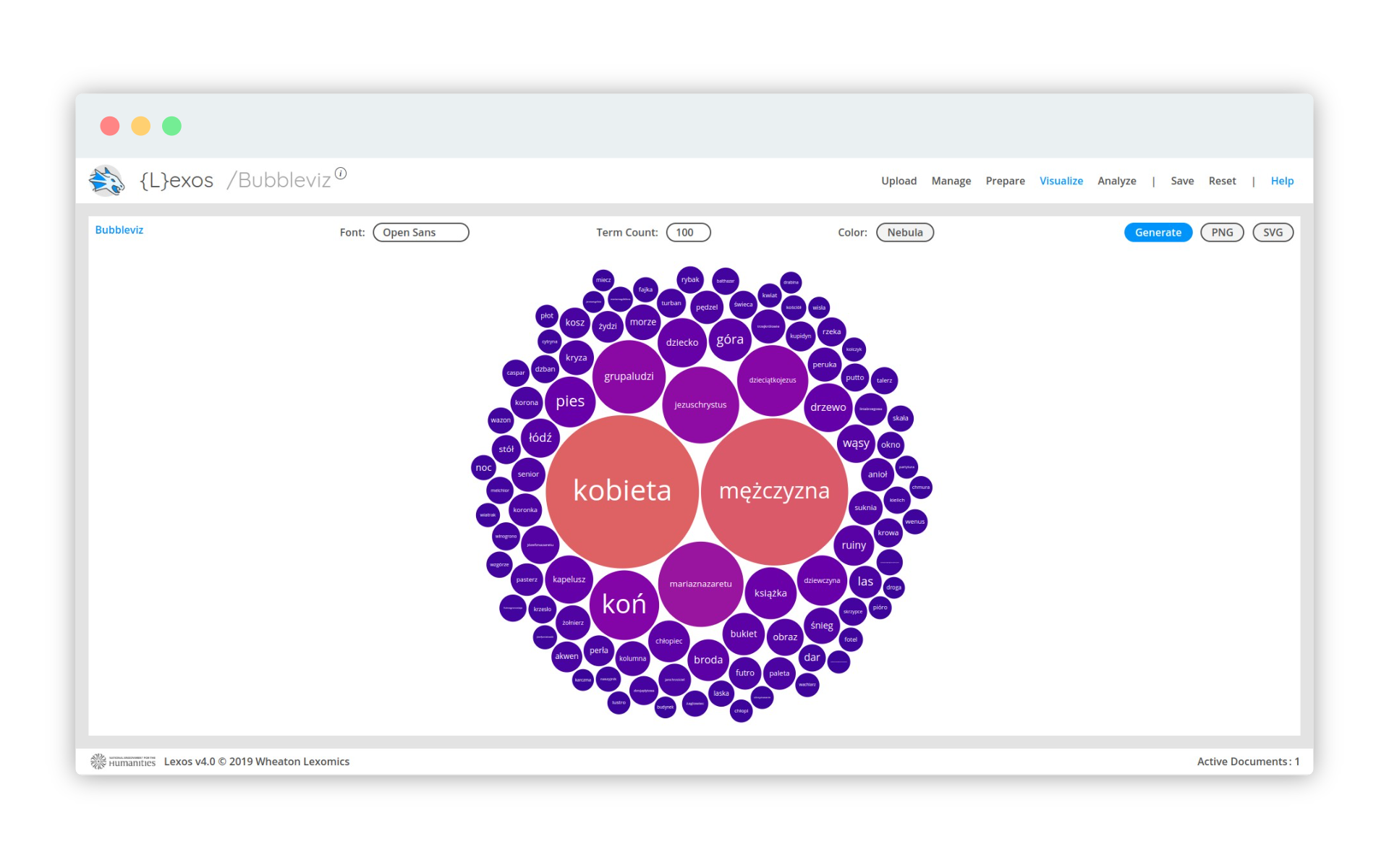
Na szczęście wizualizacja bąbelkowa, dostępna pod menu Visualize - BubbleViz, wygląda na prawidłową:
Chmury słów nie są neutralną analizą tekstu
Chmury słów kluczowych nie są neutralną analizą tekstu. Dlaczego?
Po pierwsze - sama koncepcja interpretacji tekstu. Czy rzeczywiście chmura słów zawsze pozwala na nowe, jakościowe interpretacje analizowanych treści? Jacob Harris, autor z portalu NiemanLab, będącego źródłem kompetencji dla współczesnego dziennikarstwa danych, przywołuje bardzo ciekawe przykłady ograniczeń słów kluczowych:
stworzyłem chmurę słów dokumentującą emocje wobec Tea Party na temat Obamy, i dwie największe słowa to nieprawdopodobnie like i policy, głównie dlatego, że uciążliwe słowo don’t zostało automatycznie pominięte (w porządku: takie stopwordsy w inny sposób dominowałyby w chmurze). Analiza fraz lub tematów pozwoliłaby dojść do bardziej precyzyjnych wniosków.
Wadą chmury słów - jak pokazuje Harris - jest też to, że ignoruje kontekst, w jakim używane jest dane słowo. Przykładowo, w chmurze słów wygenerowanej z raportów wojskowych z Iraku dominują słowa car i blast. Patrząc na chmurę słów nie możemy być pewni, czy raporty informują przede wszystkim o wybuchach bomb ukrytych w autach, czy też raportuje się przede wszystkim wydarzenia i sytuacje związane z zagrożeniem bombowym i samochodami (np. zaparkowanymi w niedozwolonym miejscu czy wykorzystanymi podczas ataku, niekoniecznie bombowego).
Po drugie - metody generowania. Jason Davis przygotował webowy generator chmur słów kluczowych, w którym możemy wybrać metodę wyliczania wielkości fontów dla słów. Jedna z nich opiera się na bezwzględnej liczbie wystąpień, ale dwie pozostałe to skala logarytmiczna i pierwiastek kwadratowy z liczby wystąpień. Dwie ostatnie metody mocno wpływają na wygląd chmury, spłaszczając rozkład liczebności słów, przez co najczęściej występujące słowa nie są tak mocno wyróżnione na tle pozostałych.
Wizualizacja na podstawie absulutnych wartości:

Po zastosowaniu logarytmu:

Możecie sprawdzić to samemu - dane źródłowe do tej wizualizacji dostępne są poniżej:
renesans minimalizm impresjonizm neoimpresjonizm surrealizm fowizm minimalizm ekspresjonizm surrealizm pop-art impresjonizm pop-art dadaizm minimalizm kubizm ekspresjonizm barok minimalizm dadaizm impresjonizm ekspresjonizm impresjonizm neoimpresjonizm kubizm impresjonizm barok postimpresjonizm fotorealizm surrealizm dadaizm fotorealizm kubizm postimpresjonizm neoimpresjonizm fotorealizm postimpresjonizm surrealizm postimpresjonizm neoimpresjonizm dadaizm dadaizm surrealizm impresjonizm ekspresjonizm pop-art dadaizm ekspresjonizm impresjonizm dadaizm fotorealizm ekspresjonizm fotorealizm dadaizm neoimpresjonizm kubizm fowizm dadaizm fowizm fowizm dadaizm postimpresjonizm surrealizm minimalizm kubizm fotorealizm postimpresjonizm kubizm postimpresjonizm pop-art neoimpresjonizm surrealizm surrealizm ekspresjonizm neoimpresjonizm pop-art kubizm fowizm postimpresjonizm fotorealizm kubizm ekspresjonizm fotorealizm dadaizm ekspresjonizm surrealizm minimalizm fowizm impresjonizm postimpresjonizm dadaizm fowizm pop-art barok ekspresjonizm impresjonizm minimalizm impresjonizm surrealizm fowizm surrealizm barok surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizm surrealizmI po trzecie - generując chmurę słów polegamy na oprogramowaniu. Biblioteki i mechanizmy zastosowane w programie, nie zawsze dla nas jasne, wpływają na to, jak możemy pracować z naszą wizualizacją. W tej lekcji korzystaliśmy z Lexosa, w którym użyto biblioteki d3-cloud. Ograniczenia d3-cloud sprawiły, że niektóre wizualizacje były błędne, bo nie pokazywały najczęstszych słów w naszym zbiorze.
Podsumowanie
Mimo pewnych ograniczeń i błędów udało się nam uzyskać poprawną wizualizację bombelkową najczęstszych słów, które w Wikidanych opisują treść obrazów w kolekcji MNW. Możemy ją szybko zinterpretować: Wikidane informują o obrazach o tematyce religijnej, przedstawiających osoby. Słowo koń, obecne na wysokiej pozycji w statysyce słów, sugerować może obrazy przedstawiające sceny batalistyczne albo portrety konne.
Lekcja pozwala znaleźć solidne argumenty na rzecz niestosowania chmur słów kluczowych w analizie i wizualizacji tekstów. Na pewno każdorazowe zastosowanie tej wizualizacji wymaga odpowiedniego przygotowania danych.
W trakcie lekcji zwróciliśmy też uwagę na potencjał Wikidanych jako źródła informacji o obiektach dziedzictwa.
Wykorzystanie metod
Koncepcji chmury słów kluczowych szukać można już w latach 70. - psycholog Stanley Milgram wygenerował “chmurę” nazw miejsc w przestrzeni Paryża, które były najczęściej wymieniane w przeprowadzanych przez niego wywiadach z mieszkańcami tego miasta.

Dzięki względnej łatwości przygotowania, chmury słów kluczowych są często używane w pracach naukowych. Wykorzystuje się je także jako narzędzie nawigacyjne w witrynach internetowych. Chmura słów kluczowych to także popularny szablon estetyczny.
Dobre narzędzia dla programistycznego, zaawansowanego generowania chmur słów kluczowych udostępnione są dla języka R i Python.
Pomysł na warsztat
Zaproponuj uczestniczkom i uczestnikom warsztatu wygenerowanie chmury słów z wybranego tekstu i następnie zanalizujcie ją. Co pokazuje, a co ukrywa taka wizualizacja? Jaki wpływ na jej kształt ma metoda wyliczania wielkości fontów i oprogramowanie? Zastanówcie się, czy są takie kategorie tekstów, których nie da się dobrze zwizualizować za pomocą chmury słów.


